
Large Language Models (LLM) have been revolutionizing the field of Artificial Intelligence. Still, powering these computational titans can pose quite the challenge. Take LLaMA-13B served with HuggingFace Transformers for instance, which can only tackle a modest 6.4 requests per minute on the high-end A100 GPU. This bottleneck results in lengthy wait times for users, and at about $10 per 1,000 requests, a significant cost for any organization.
Our recent project, vLLM, an open-source library developed at UC Berkeley, ensures fast and efficient LLM inference. Thanks to our new PagedAttention algorithm, vLLM has taken LLM serving’s speed to the next level (24x higher throughput than HuggingFace Transformers), making LLM affordable even for teams with limited resources. Check out vLLM’s blog post and GitHub repository for more details.
In this post, we show:
- A one-click recipe to serve LLMs with our vLLM system in your own cloud, using SkyPilot
- How SkyPilot helped us focus on AI and forget about infra (and why other LLM projects should use it!)
Launching vLLM in Your Cloud with One Click
We’ve made it incredibly easy by providing a simple SkyPilot yaml serve.yaml to launch vLLM (check out the detailed instructions here). With just one SkyPilot command, you can launch vLLM for LLaMA-65B on any cloud, in your own cloud account:
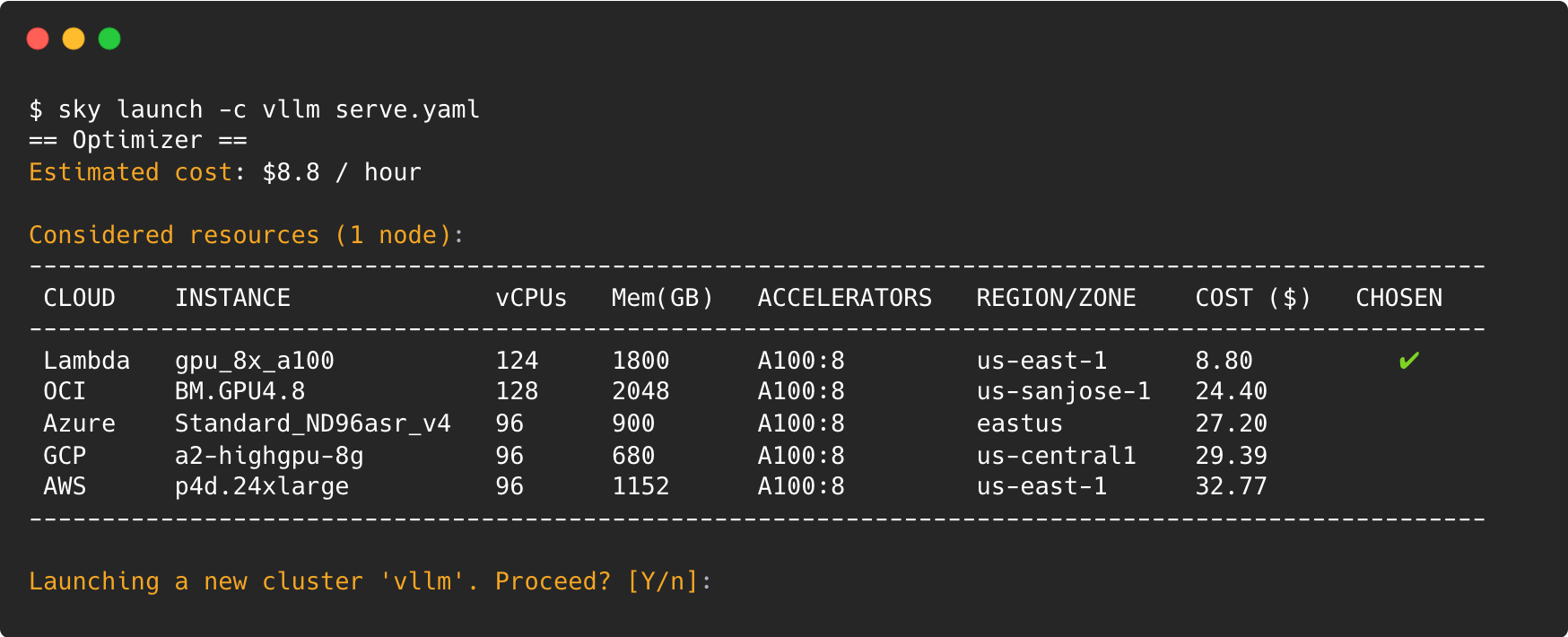
sky launch -c vllm serve.yaml
SkyPilot will spin up a cluster on the cloud with the best price and availability of the required 8 A100 GPUs to start the vLLM serving:
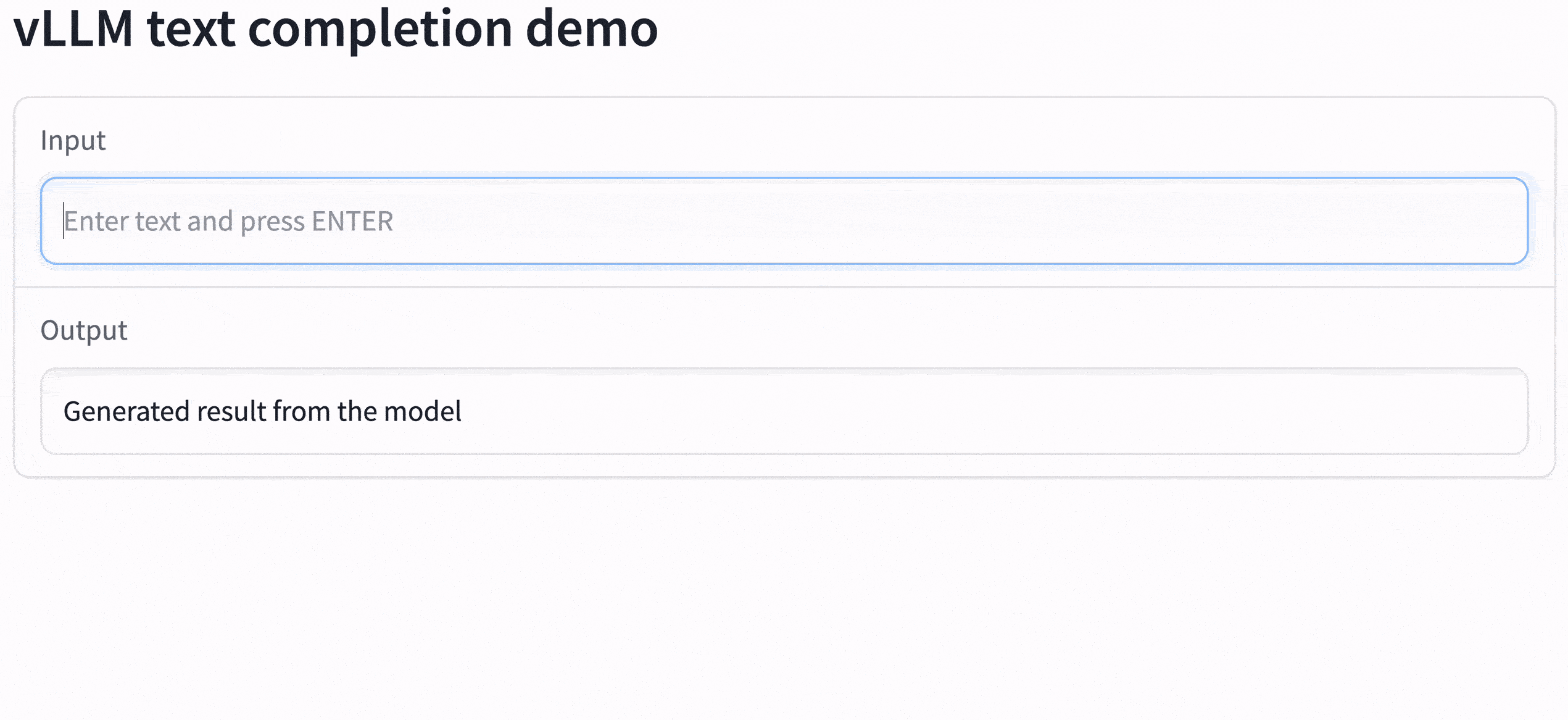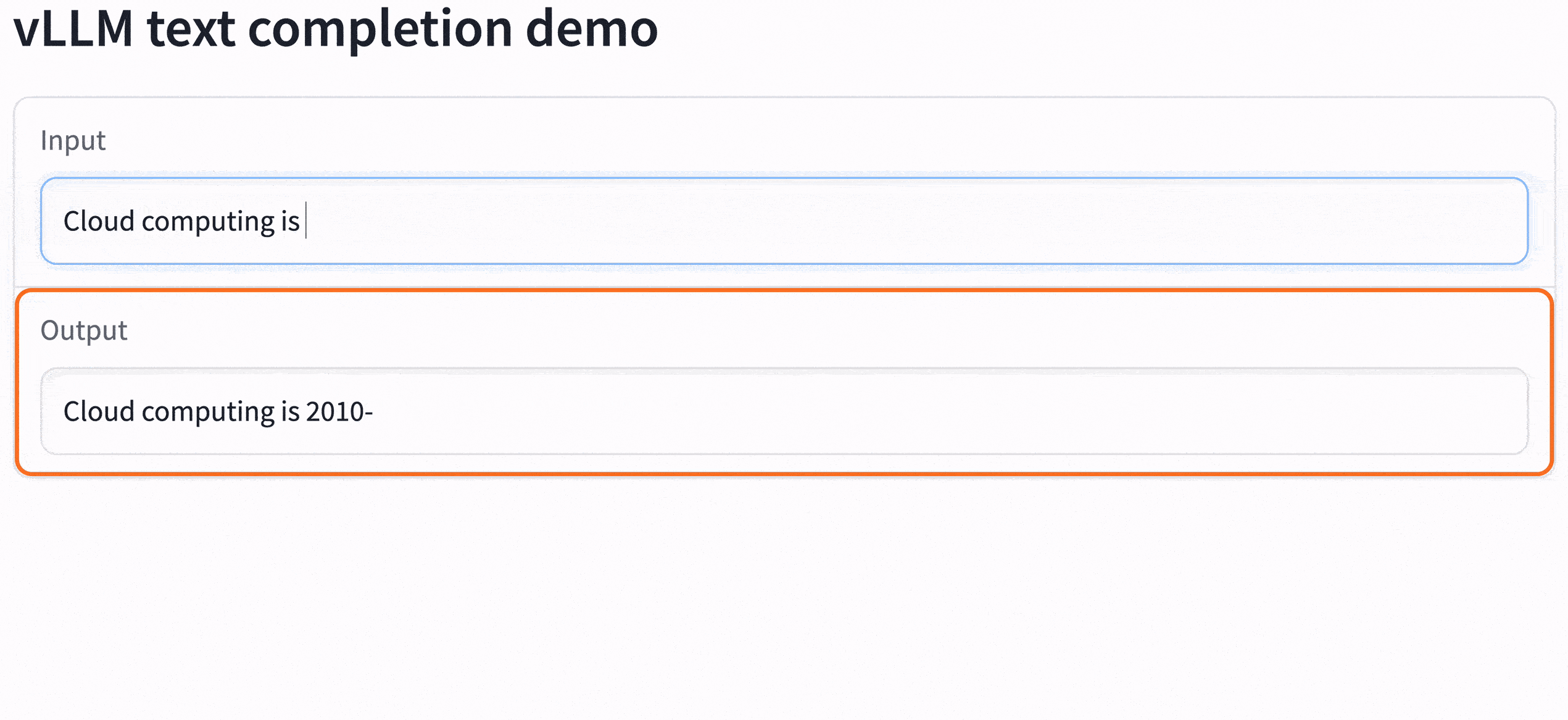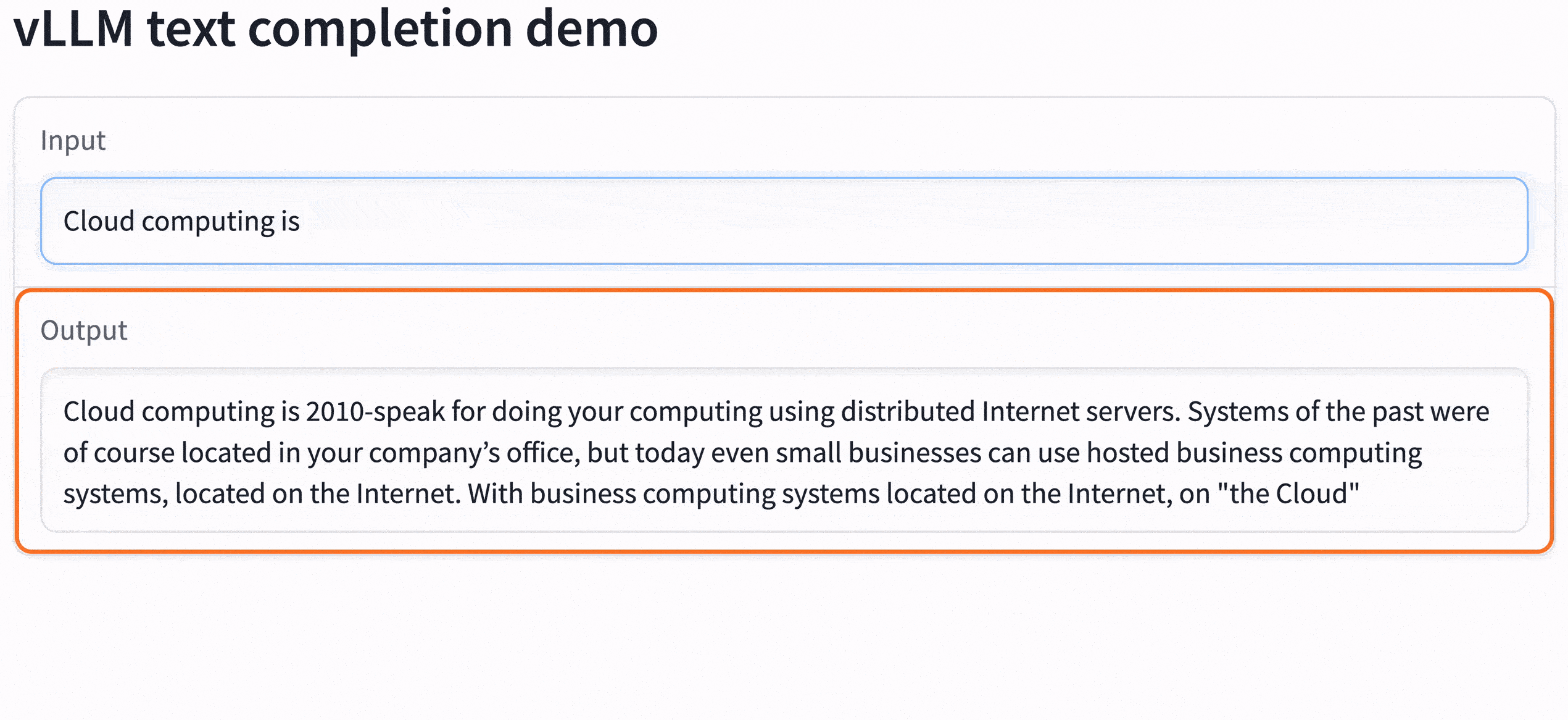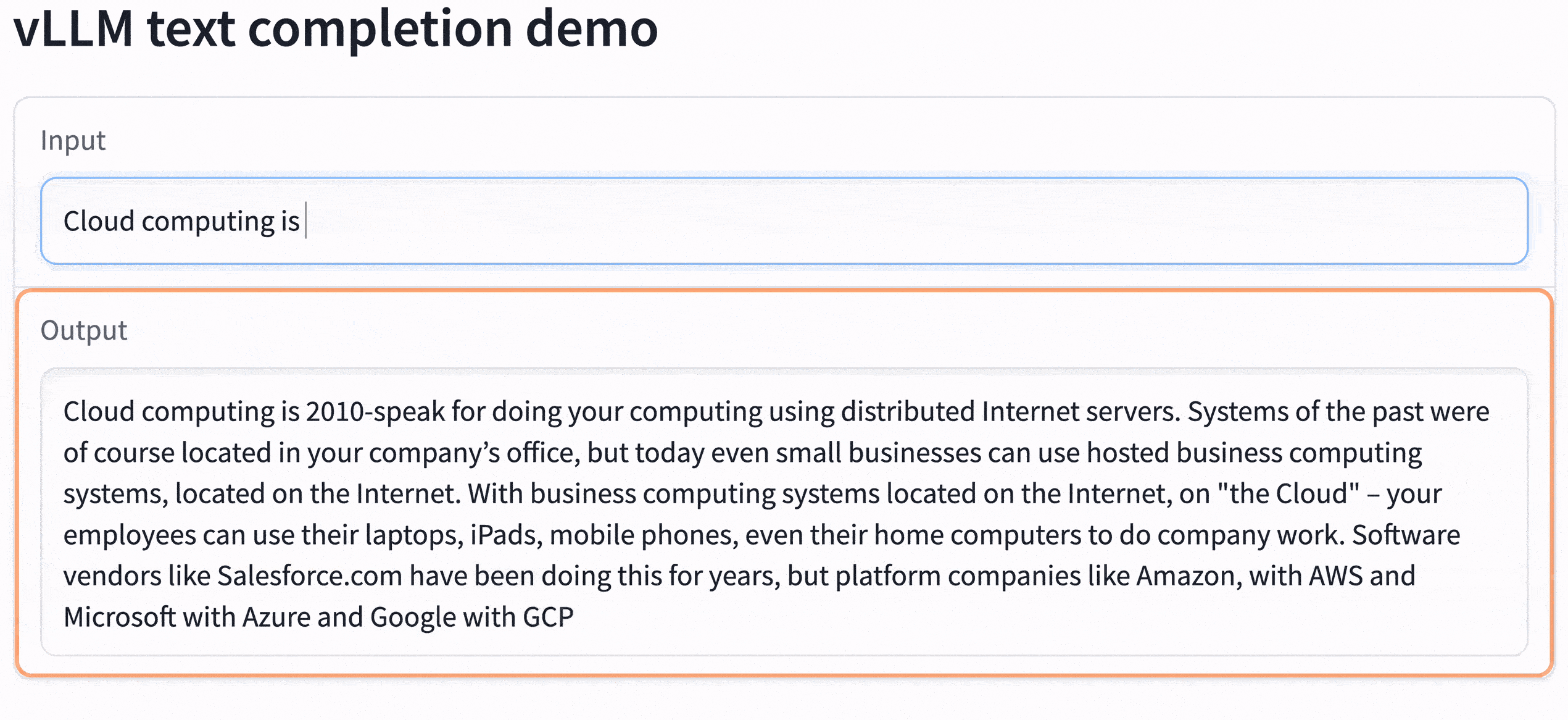
Click on the URL in the job output (look for the string https://xxxxx.gradio.live). The model is now accessible and served with incredible speed:
To try it out with a smaller model, like LLaMA-13b and less demanding GPU resources, like a single A100, slightly changing the command will magically work:
sky launch -c vllm serve.yaml --gpus A100 --env MODEL_NAME=decapoda-research/llama-13b-hf
How SkyPilot Accelerated vLLM’s Development On the Cloud
During our development of vLLM, we encountered several pain points in terms of provisioning and using cloud GPUs.
Fortunately, we started using SkyPilot to run experiments on a daily basis, which removed the cloud infra burdens and enabled us to focus on developing vLLM and and running LLM jobs, i.e., the fun part!
We discuss the pain points we encountered below and show the solutions we found in SkyPilot, which we believe would also help accelerate other LLM projects/practitioners:
Confronting the GPU Shortage
LLMs typically require high-end GPUs such as the coveted A100-40GB or A100-80GB GPUs. Unfortunately, recently we have witnessed a significant GPU shortage in the cloud. Searching for GPU instances in different regions (or clouds!) often felt like a never-ending treasure hunt.
Imagine the hassle of manually searching for available GPU VMs in dozens of regions across major clouds like AWS, GCP, Azure, not to mention other clouds like Lambda Cloud, Oracle Cloud, etc. Simply to find an instance with 8 A100 GPUs could take us over an hour!
With SkyPilot, we used its automatic failover feature to entirely automate this process. A single command and SkyPilot would automatically loop through all regions and clouds we have access to, provision the cheapest available instance, set up the VM, and run our job.
Mitigating High Costs
Another hurdle was the high costs of GPUs in the cloud. An instance with 8 A100s costs about $30/hour. What’s worse? In an attempt to secure the hard-to-find instances, we were reluctant to stop/terminate instances even if they became idle, resulting in even higher costs for mere reservation.
Enter SkyPilot. Its ability to auto-search for available instances across all clouds meant we could confidently use its autodown feature to eliminate unnecessary costs once our jobs were done.
# Automatically terminate the cluster after all jobs on the cluster ‘vllm’ finish
sky autostop --down vllm
Furthermore, even when we were using only one cloud, SkyPilot by default uses the cheapest region in the given cloud, saving us up to 20%.
Efficient Cluster Management
SkyPilot proved invaluable when we had to manage multiple clusters for our experiments. Without it, tracking clusters across various regions and clouds would have been very tedious.
With the sky status command, all clusters can be effortlessly viewed within a single table–this works for all our development clusters which were scattered across regions and clouds. Commands such as sky stop/down/start enable us to manage our clusters no matter which clouds/regions they are in, without ever needing to go to different cloud consoles.

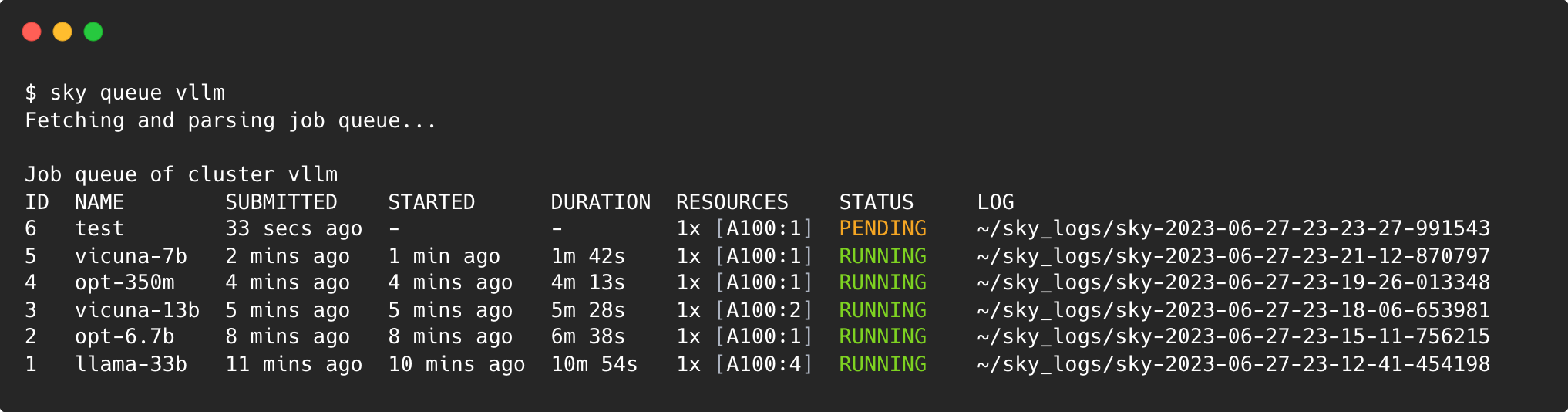
Scaling Out Easily
When we were ready to scale out (e.g., run 1000s of jobs for experiments), SkyPilot provides a job queue on any cluster out-of-the-box. We wrote a simple Python script to generate 1000s of job variations to run and submitted them to our SkyPilot cluster(s) using the sky exec call (in Python, sky.exec()). All of our jobs were scheduled automatically based on their resource requirements (e.g., 8 concurrent jobs per node, each taking 1 GPU).
Summary
In this post, we first shared a simple way to launch vLLM on any cloud with just one command; see the fully launchable example here. Try it out and see if it accelerates serving your LLMs by up to 24x!
Further, we shared our concrete experiences developing vLLM on the cloud, with the help of SkyPilot. Our goal was to iterate quickly and build an efficient LLM inference system, and we did not want to deal with any of the cloud infrastructure challenges: GPU shortage, high GPU costs, or managing many clusters and jobs. Thanks to SkyPilot, we were able to completely offload these burdens while making vLLM’s development more cost-effective.
We hope the example and experiences we shared benefit the LLM community. Here’s to many more AI innovations ahead!