Mixtral 8x7B is a high-quality sparse mixture of experts model (SMoE) with open weights from Mistral AI. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. Mistral.ai uses SkyPilot as the default way to deploy their new model with an OSS stack. The instruction in their doc is a basic way for serving the model on a single instance with an exposed port. In this blog post, we show a more advanced way to use SkyPilot to scale up the serving in production, with the best GPU availability and lower cost.

Serving with a Bare VM is not Enough for Production
A first intuitive way people come up with for serving a model on the cloud would be starting a new VM that has an exposed port to the public, and serving the model on that port. This is easy to do with SkyPilot, as described in Mistral.ai’s official doc. A more detailed YAML can also be find in our SkyPilot examples here:
resources:
cloud: GCP
region: us-central1
accelerators: A100-80GB:2
ports:
- 8000
setup: |
conda activate mixtral
if [ $? -ne 0 ]; then
conda create -n mixtral -y python=3.10
conda activate mixtral
fi
# We have to manually install Torch otherwise apex & xformers won't build
pip list | grep torch || pip install "torch>=2.0.0"
pip list | grep vllm || pip install "git+https://github.com/vllm-project/vllm.git"
pip install git+https://github.com/huggingface/transformers
pip list | grep megablocks || pip install megablocks
run: |
conda activate mixtral
export PATH=$PATH:/sbin
python -u -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE | tee ~/openai_api_server.log
With a single command, the model can then be accessed using the IP and port of the cluster:
sky launch -c mixtral serve.yaml
IP=$(sky status --ip mixtral)
curl http://$IP:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
"prompt": "My favourite condiment is",
"max_tokens": 25
}'
This works perfectly fine for testing out the new model.
However, in production, we may experience several issues:
- GPU availability: The availability of the specified GPUs (
A100:2, 2x A100 40GB GPUs) can be bad due to the recent GPU shortage, which can cause significant time for searching and waiting for the available resources. - Monitoring the service: It is a huge manual burden to monitor, detect, and recover from any downtime of the service caused by transient issues.
- High cost: Cost of serving the model can be significant with the high-end GPUs.
SkyPilot has identified and solved these pain points with LLM serving on the cloud:
- We have shipped the “multiple resources” feature to further improve GPU availability; and
- We have released the SkyServe library as part of SkyPilot to handle the operations of scaling AI Serving on the cloud(s).
These recent additions have been serving 10+ open models of Chatbot Arena from LMSYS.org. The system has been running in production for months for Chatbot Arena. Please stay tuned for another release blog of SkyServe.
In this blog, we will take Mixtral as an example to show how SkyPilot and SkyServe mitigate the above problems for real-world LLM serving.
Expanding the search space to find GPUs
SkyPilot helps you serve Mixtral – or any finetuned LLM / custom model – by automatically finding available GPUs on any cloud, provisioning the VMs, opening the ports, and serving the model.
Due to the GPU shortage, the first question for deploying a model in your own cloud is: Where and how can I find GPUs?
In the SkyPilot YAML above, where we fully specify the cloud, region, and accelerator to use, the search space where SkyPilot finds GPUs is limited:
resources:
cloud: gcp
region: us-central1
accelerators: A100-80GB:2
As such, a smaller search space can cause a long cold start time due to waiting for the specific GPUs to become available in the specific region.
To mitigate this, SkyPilot now allows you to significantly expand the search space of each provisioning request by leveraging multiple locations and GPU choices:
Step 1: Allowing many regions
A cloud provider normally has multiple regions, and different regions will have different resource pools. So the first thing we can do is to remove the region field, allowing SkyPilot to automatically go through different regions in the cloud while performing price optimization to find the cheapest available resources.
resources:
cloud: gcp
# Remove region spec to allow optimizing over all regions in the cloud:
# region: us-central1
accelerators: A100-80GB:2
Note that in LLM serving, the latency bottleneck is mostly caused by the model inference (more than 2s) instead of the network latency for contacting different regions (less than 200ms). Therefore, allowing multiple regions will have a negligible effect on the response time.
If a user wants to use only certain regions (e.g., US regions only) , we can also use the newly supported syntax to reduce the candidates:
resources:
cloud: gcp
accelerators: A100-80GB:2
# Leverage two regions to expand the search space:
any_of:
- region: us-central1
- region: us-east1
Step 2: Allowing many clouds
As different cloud providers have different availability of the GPUs in their data centers, searching available GPUs across clouds (all clouds you have access to) can further increase the chance for the job to find the GPUs required.
We can do this by leaving out the cloud field in the resources specification. With this, SkyPilot will search through all possible resource pools enabled for you (e.g., 3x more potential resources if 3 clouds are enabled):
resources:
accelerators: A100-80GB:2
# No `cloud` or `region` set means utilize all clouds you have access to!
Step 3: Allowing multiple candidate accelerators
To further improve GPU availability, we identified that serving workloads typically can run on different GPUs. For example, the Mixtral model can be served on L4:8, A10G:8, A100-80GB:2, etc.
SkyPilot enables a user to specify a set of accelerators to be used for running the model, with the semantics of “any of these is okay”:
resources:
# SkyPilot performs cost & availability optimizations on this set of
# GPUs. The probability of successfully getting *any* of these
# GPUs also becomes much higher.
accelerators: {L4:8, A10g:8, A10:8, A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
With this configuration, SkyPilot will automatically find the cheapest accelerators among the candidates that are available on the cloud and serve the model.
SkyServe: Scaling Model Serving with Multiple Replicas
When scaling up is required, SkyServe is the library built on top of SkyPilot, which can help you scale up the serving with multiple instances, while providing a single ingress endpoint and automatic load balancing and recovery of replicas.
To serve Mixtral with multiple instances, run the following command to start the service and have SkyServe automatically monitor and manage it:
sky serve up -n mixtral ./serve.yaml
How do we get serve.yaml? Simple. Just add a service spec to a regular SkyPilot YAML such as the one described in the last section. The additional arguments for serving specifies the way to check the readiness of the service and the number of replicas to be used for the service:
service:
readiness_probe:
path: /v1/chat/completions
post_data:
model: mistralai/Mixtral-8x7B-Instruct-v0.1
messages:
- role: user
content: Hello! What is your name?
initial_delay_seconds: 1200
replica_policy:
min_replicas: 2
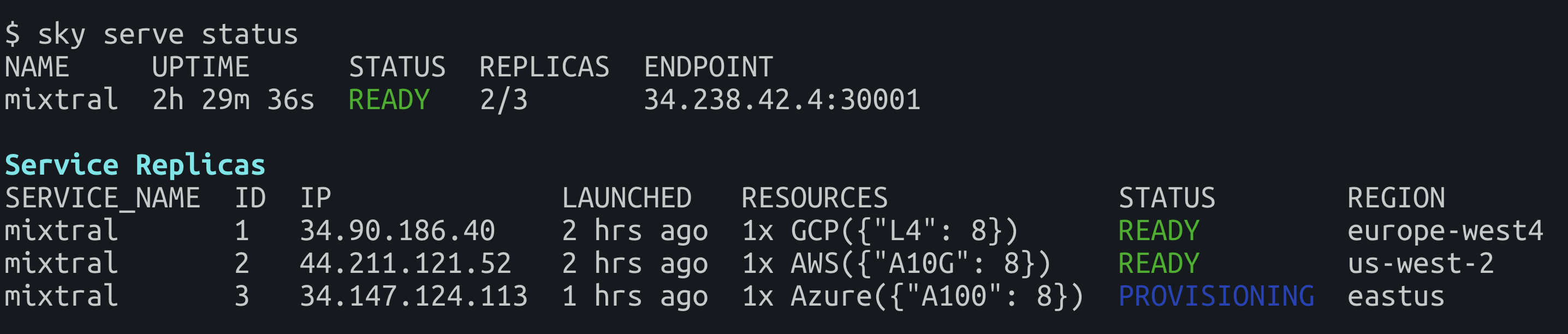
After sky serve up finishes, we are able to get a single endpoint to access the models served on any of the replicas.
ENDPOINT=$(sky serve status -endpoint mixtral)
curl -L http://$ENDPOINT/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
"prompt": "My favourite condiment is",
"max_tokens": 25
}'
Although the interfaces looks similar for serving on a single instance, the SkyServe library significantly improves the robustness of the services to be served:
- Automatic monitoring and recovery: SkyServe will start a control plane that keeps monitoring the healthiness of the service and automatically recover the service whenever a failure occurs, so no manual monitoring is required.
- A single endpoint is created and the request traffic will be redirected among multiple replicas with automatic load balancing, so that more requests can be handled than a single instance solution.
- Leveraging GPU availability across multiple clouds: Based on SkyPilot, SkyServe could easily utilize the GPU availability across multiple clouds, without additional involvement from the users.
Reducing Costs Further with Spot Instances
To further save the cost by 3-4x, SkyServe allows using spot instances as replicas. SkyServe automatically manages the spot instances, monitors for and preemptions, and restarts replicas when needed.
To do so, simply add use_spot: true to the resources field, i.e.:
resources:
use_spot: true
accelerators: {L4:8, A10g:8, A10:8, A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
Note that due to the lack of guarantees of spot instances, using spot instances can cause degraded performance or downtime of the services during the recovery of the instances after preemptions. That said, stay tuned for upcoming policy in SkyServe that will optimize costs using spot instance replicas while ensuring service level objectives!
Learn More
SkyPilot enhances LLM serving, providing solutions for GPU scarcity, service reliability, and cost optimization. This post illustrates how SkyPilot and its SkyServe library can be effectively used in a real-world LLM serving scenario.
Next steps
- With all changes above adopted, you can find the complete YAML for serving the Mixtral model here.
- To serve other open-source or your own AI models, please check out more examples in LLM and Examples folder in the SkyPilot repository.
- If you have any questions about the system, please checkout the SkyPilot docs, our GitHub issues, or directly contact us on our Slack workspace.