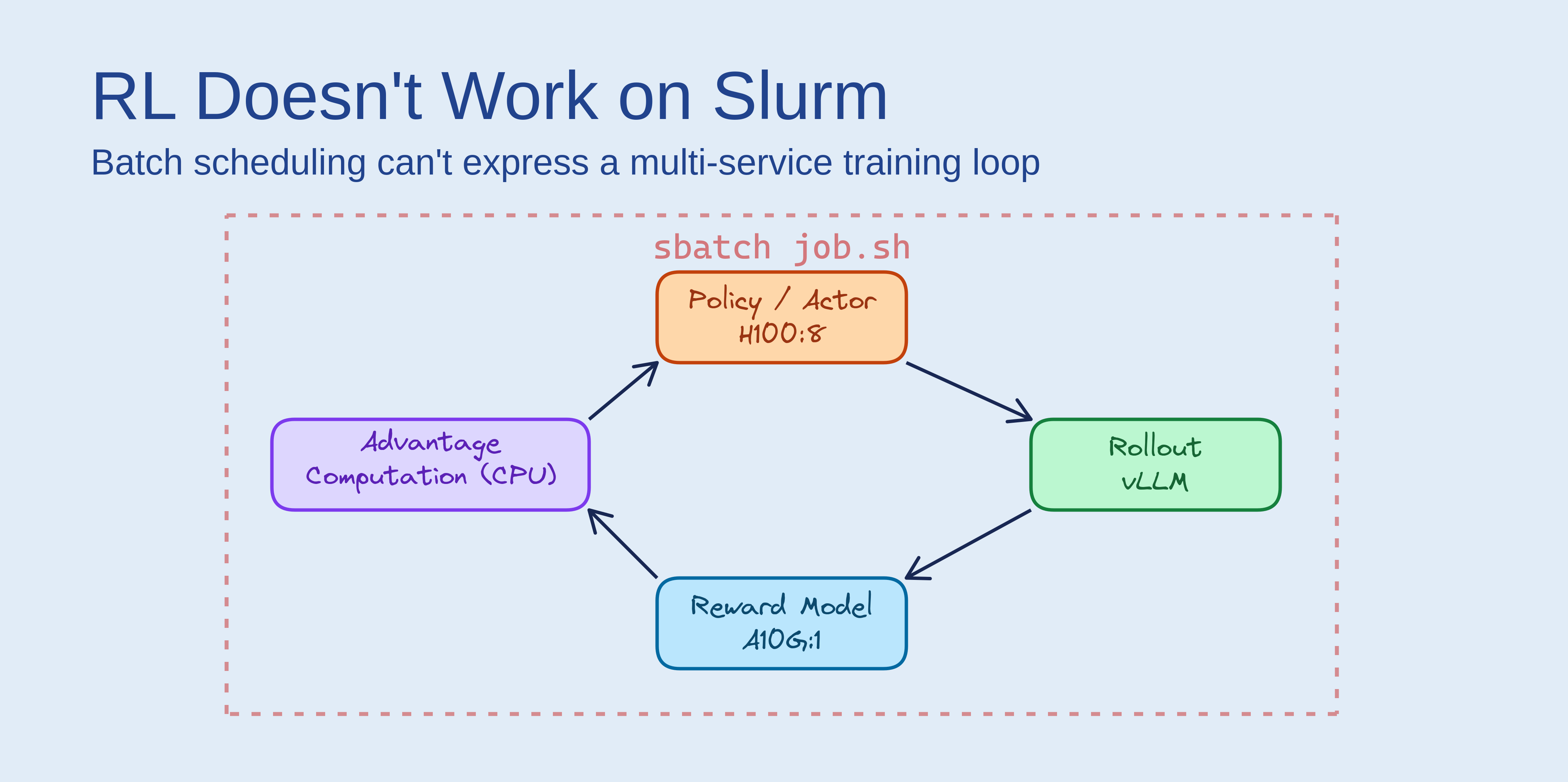
Open the Slurm launch script for OpenRLHF. It parses node IPs from scontrol show hostnames, hardcodes service addresses, and bootstraps a Ray cluster by hand. Now open the one for veRL. Same thing. NeMo RL? Same thing again. Three unrelated frameworks, three sets of nearly identical glue code, all papering over Slurm’s lack of multi-service orchestration.
Slurm is a batch scheduler. Online RL - GRPO, PPO, multi-step RLHF - is not a batch job. Writing better launch scripts doesn’t change that.
What a typical online RL pipeline looks like
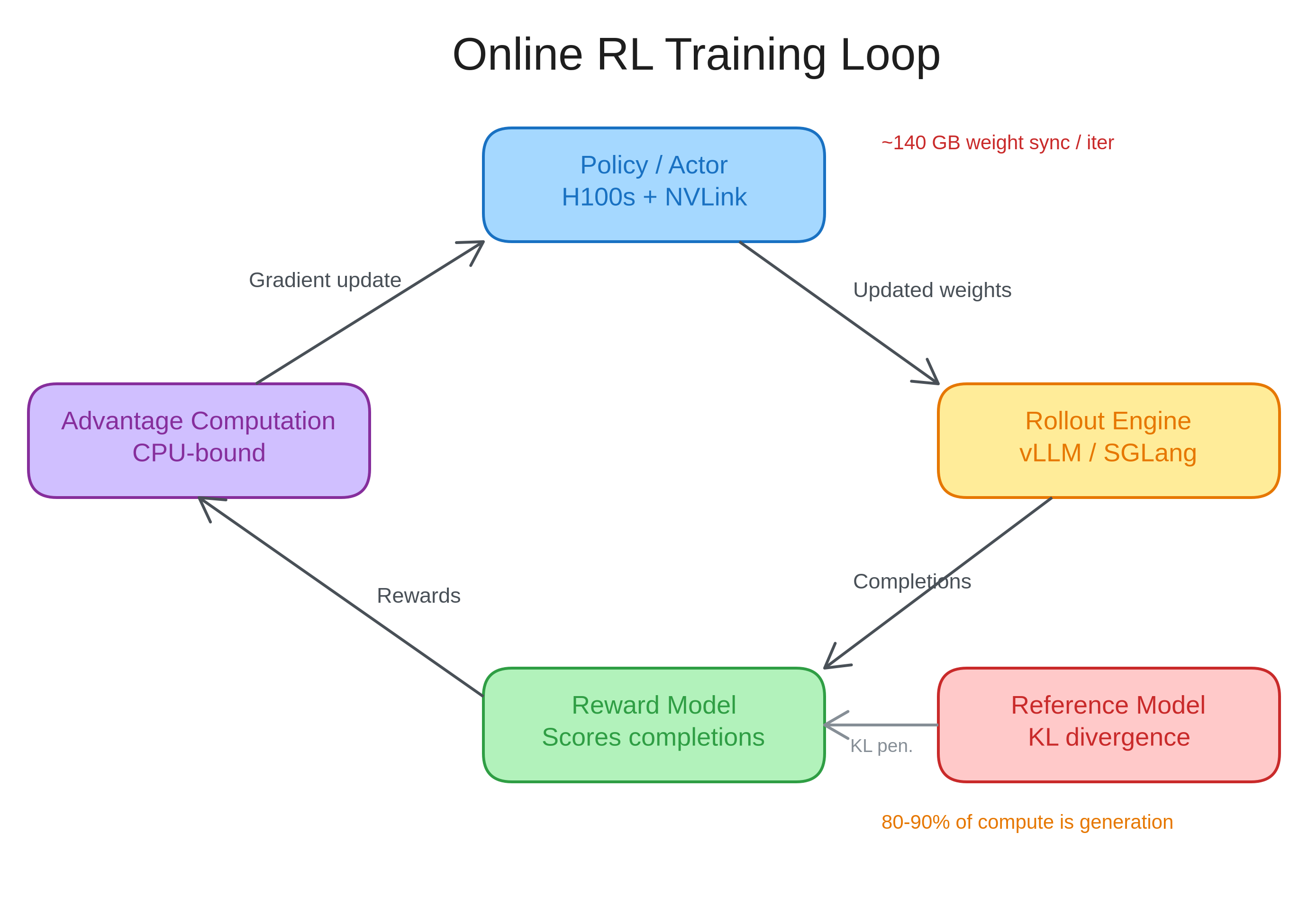
A GRPO or PPO training loop isn’t one program. It’s four or five separate processes that need to coordinate on every iteration.
The policy/actor model is where gradient updates happen - you need H100s or B200s with NVLink and InfiniBand here. The rollout engine (usually vLLM or SGLang) generates completions from the current policy; it’s memory-bandwidth-bound, not compute-bound, so cheaper GPUs work. Then there’s the reward model (or a verifiable reward function) and a reference model for KL divergence penalties - both inference-only, each needing its own GPU allocation. Finally, data processing (tokenization, advantage computation, replay buffers) runs on CPU.
These aren’t independent jobs. The rollout engine produces completions, the reward model scores them, advantages get computed, the policy takes a gradient step, and then the updated weights have to ship back to the inference engine before the next iteration can start. With a 70B model, that’s ~140GB of fp16 weights moving every single iteration.
Generation is where the time goes. 80–90% of total compute in RL training is spent on rollout generation. The gradient updates themselves are comparatively fast.
Why GRPO made this worse
DPO learns from a static preference dataset, structurally identical to supervised fine-tuning. It maps perfectly fine to a Slurm batch job: read data, compute gradients, update weights, repeat.
GRPO, first introduced in DeepSeekMath and later adopted by DeepSeek-R1, works differently. Instead of learning from pre-collected preferences, GRPO samples multiple completions from the current policy during training, scores them, and computes group-relative advantages. The advantage for each completion is (reward - group_mean) / group_std. No learned critic network (unlike PPO, which trains both a policy and a value network), which cuts memory overhead.
But now training and inference are inseparable. You can’t precompute the completions offline because the rewards are relative to what the current policy produces. Every training step requires fresh generations from the live model. Slurm has no way to express this kind of coupling between inference and training.
Where Slurm’s model breaks down
Slurm manages over 60% of the TOP500 supercomputers. Its core assumption: a job is a finite program with a defined end time, running on exclusively allocated nodes. Online RL breaks this:
No service discovery. Slurm gives you SLURM_JOB_NODELIST, a list of allocated hostnames, and nothing else. No DNS, no service registry. When OpenRLHF runs on Slurm, its launch scripts must extract node IPs via scontrol show hostnames, parse them into arrays, and manually bootstrap a Ray cluster with hardcoded addresses (example). There is no way in Slurm to say “run the actor on these GPUs, the reward model on those, vLLM inference on these others, and let them talk to each other.”
Jobs must terminate. Every Slurm partition has a MaxTime limit; users must specify --time. As Nebius engineers note, “Slurm is well-suited only for time-finite workloads on size-limited clusters.” An RL training loop runs until convergence, which has no predictable wall-clock deadline. Fitting it into Slurm means either grossly overestimating time (wasting your allocation) or checkpointing and resubmitting, requiring a full topology reconstruction each time.
Health checking stops at the node. Slurm monitors whether slurmd responds to periodic pings, but it does not provide a component-level recovery loop for services inside the allocation. If your reward model or vLLM server dies, Slurm has no automatic way to restart just that service, reattach it to the rest of the job, and preserve its endpoint. At best, you fail or requeue the whole job; then your launch script has to redo service discovery, rebuild the Ray topology, and redistribute hardcoded addresses. In SkyPilot Job Groups, the job system owns those mechanics: tasks get stable hostnames, recover independently from preemptions, and can be relaunched by managed job recovery policies instead of forcing user scripts to reconstruct topology by hand.
Heterogeneous jobs exist but barely. Slurm introduced hetjobs in version 17.11 (2017), allowing jobs with components on different partitions. But the limitations are severe: hetjobs are only scheduled by the backfill scheduler, all resources are locked at allocation start with no elasticity, and you cannot restart one component without killing the others. The official docs warn of self-starvation when components request overlapping partitions.
No dynamic scaling. Slurm clusters are fixed pools. You can’t add inference workers mid-job when generation becomes the bottleneck, or release training GPUs during the generation phase. The StreamRL paper shows that generation time grows faster than training time as RL progresses, so the optimal resource ratio shifts during a single run. Slurm has no mechanism for this.
How every major framework works around it
Every popular RL framework has had to solve the same problem: Slurm allocates nodes, but something else needs to manage the components running on them. The solutions differ in their approach, but they all end up building an orchestration layer that Slurm doesn’t provide.
OpenRLHF
OpenRLHF disaggregates Actor, Critic, Reward, and Reference models across GPUs, using vLLM for inference and DeepSpeed ZeRO-3 for training. Its hybrid engine scheduling (vLLM during generation, DeepSpeed during training) is the core design. Weight synchronization between training and inference happens via NCCL or CUDA IPC. On Slurm, the launch scripts parse node IPs from scontrol, hardcode service addresses, and manually wire everything together. OpenRLHF has been adopted by Google, ByteDance, Alibaba, and the Berkeley Starling Team.
veRL
veRL (Volcano Engine RL, from ByteDance) takes a different approach to weight synchronization. Its 3D-HybridEngine reshards model weights in-place between training layout (e.g., FSDP with data parallelism=2, tensor parallelism=8) and inference layout (vLLM with DP=16, TP=4) on the same GPUs, avoiding a duplicate copy of the model. This cuts transition overhead by up to 89% for 70B models, and achieves 3.25x–12.5x throughput over prior frameworks in PPO benchmarks. veRL scales to 671B-parameter models across hundreds of GPUs. On Slurm, it still needs external tooling to bootstrap the cluster and manage component placement; Slurm handles node allocation and nothing more.
NeMo RL
NVIDIA’s original RL framework, NeMo-Aligner, used PyTriton to expose the Critic and Reward Model as HTTP servers that the PPO actor coordinated with. On Slurm, this required launching multiple coordinated srun commands with manual service wiring. As of May 2025, NeMo-Aligner is deprecated. Its replacement, NeMo RL, moved to a distributed scheduling model with vLLM or Megatron inference for generation. The evolution is telling: even NVIDIA’s own framework outgrew what Slurm could coordinate natively.
TRL
TRL (Hugging Face) originally ran all components within a single process on co-located GPUs, sidestepping the multi-service problem entirely. In April 2025, TRL added a vllm_mode="server" option that runs vLLM as a separate process on dedicated GPUs, with NCCL weight synchronization between trainer and inference server. TRL’s docs now include a multi-node Slurm example that trains Qwen2.5-72B across four training nodes plus a dedicated vLLM server node using DeepSpeed ZeRO-3. An experimental AsyncGRPOTrainer further decouples generation from training with a background worker streaming completions from an external vLLM server.
For smaller models on a single node, TRL’s default co-located mode still works fine on Slurm. But at 70B+ scale, TRL hits the same disaggregated architecture and the same Slurm orchestration challenges as the other frameworks.
Teams that hit this wall
Meta presented at SCALE 22x (2024) about their active migration from Slurm to Kubernetes for AI research infrastructure. They built custom abstraction layers to hide K8s complexity from researchers while getting the orchestration and autoscaling that Slurm couldn’t provide.
The Slurm-on-Kubernetes trend is another symptom. Multiple organizations have independently built systems to run Slurm inside Kubernetes: CoreWeave’s SUNK, Nebius’s Soperator, Character.ai’s Slonk, and Slinky from SchedMD (now NVIDIA). Researchers want Slurm’s familiar interface and fair-share scheduling; infra teams need Kubernetes for orchestration, health checks, and autoscaling. Character.ai’s team said the hard part is synchronizing Slurm’s resource view with Kubernetes’s. Each of these projects took months of engineering, and they all exist because Slurm alone can’t handle dynamic, multi-service workloads. (We covered this in more depth in our Slurm vs K8s and GPU Neoclouds posts.)
Danijar Hafner, creator of the Dreamer world-model algorithms, described the problem as: “Our jobs are too complicated to manually start and stop the different services. There are learners, actors, envs, data loaders, replay buffers, etc.” His workloads needed V100s for data processing, H100s for training, high-RAM CPU nodes for replay buffers, and high-CPU nodes for environment workers: all as a single managed job. No Slurm configuration can express that.
H Company, an AI lab running 2,000+ GPUs across multiple clouds, initially relied on Slurm for SFT and DPO. When they moved to online RL, a researcher noted: “Slurm worked fine for SFT. However, to support online RL, we had to run the trainer on K8s so it could communicate with our custom vLLM inference server.” They ended up maintaining duplicate infrastructure: Slurm scripts and Kubernetes manifests describing the same training logic.
Some organizations avoided this problem entirely. OpenAI scaled Kubernetes to 7,500 nodes for GPT-3, CLIP, and DALL-E without ever using Slurm. Google uses Borg (Kubernetes’ predecessor), and their Menger RL infrastructure scales to several thousand actors across multiple clusters.
Running RL with SkyPilot Job Groups
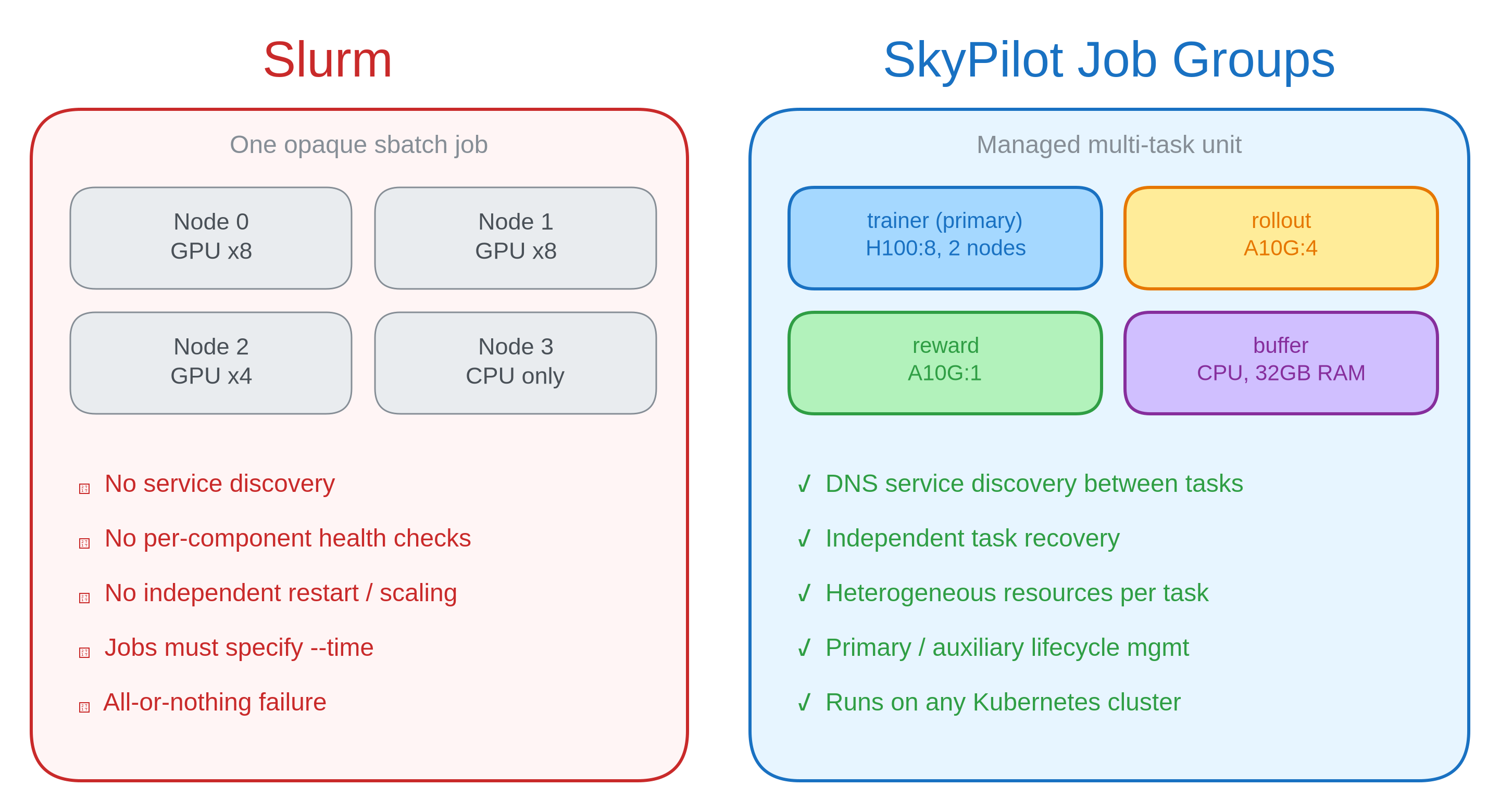
The workarounds above all exist because Slurm cannot launch multiple heterogeneous, communicating tasks as a single managed unit. SkyPilot Job Groups are one way to address this.
A Job Group is a multi-document YAML file where each document defines one task with its own resource requirements. A header section specifies which tasks are primary (driving job completion) and which are auxiliary (services that persist until primary tasks finish).
Here’s what an RL pipeline looks like:
# Header: job group metadata
name: rl-training
execution: parallel
primary_tasks:
- trainer
termination_delay: 30s
---
# Trainer: runs PPO/GRPO updates on high-end GPUs
name: trainer
resources:
accelerators: H100:8
num_nodes: 2
run: |
python train.py \
--rollout-host rollout-0.${SKYPILOT_JOBGROUP_NAME} \
--reward-host reward-0.${SKYPILOT_JOBGROUP_NAME}
---
# Rollout engine: vLLM inference for generation
name: rollout
resources:
accelerators: A10G:4
run: |
vllm serve $MODEL --host 0.0.0.0
---
# Reward model: scores completions
name: reward
resources:
accelerators: A10G:1
run: |
python reward_server.py
---
# Replay buffer: CPU-only
name: buffer
resources:
cpus: 4+
memory: 32+
run: |
python replay_buffer.py
Launch with sky jobs launch rl-training.yaml.
Each task discovers others via DNS: {task_name}-{node_index}.{job_group_name}. The trainer reaches the rollout engine at rollout-0.rl-training, the reward model at reward-0.rl-training, etc. SKYPILOT_JOBGROUP_NAME is injected into every task for dynamic address construction.
When the trainer (the primary task) finishes, SkyPilot waits 30 seconds (the termination_delay), then tears down the auxiliary services. If any task gets preempted, SkyPilot recovers it independently without cascading failures to the other components.
Here’s how the RL components map to Job Group tasks:
| RL component | SkyPilot task | Resources | Role |
|---|---|---|---|
| Policy/actor | trainer | H100:8, 2 nodes | Primary (drives completion) |
| Rollout engine | rollout | A10G:4 | Auxiliary (inference service) |
| Reward model | reward | A10G:1 | Auxiliary (scoring service) |
| Replay buffer | buffer | CPU, 32GB RAM | Auxiliary (data service) |
The same YAML runs on any Kubernetes cluster supported by SkyPilot.
H Company adopted Job Groups to eliminate their duplicate Slurm/K8s infrastructure. They now run a primary trainer on GPU nodes alongside a CPU-only evaluation watcher that spawns GPU jobs on demand, all managed as one unit.
For concrete examples of running the RL frameworks discussed earlier with SkyPilot, see the ready-to-use configs for OpenRLHF and veRL (including tool-augmented search workflows).
The case for keeping Slurm
Slurm still has real strengths. Gang scheduling is its default behavior; Kubernetes needs add-on schedulers like Volcano or Kueue. A Slurm job is 6 lines of bash versus 60+ lines of Kubernetes YAML with ConfigMaps, Secrets, PVCs, and ServiceAccounts. Slurm natively understands cluster topology via topology.conf to co-locate GPUs for optimal NCCL performance. And once it allocates your GPUs, they’re exclusively yours.
For tightly-coupled distributed pretraining, Slurm works well. The container story has improved with NVIDIA’s Enroot and Pyxis. And NVIDIA’s acquisition of SchedMD in December 2025 suggests they plan to keep investing in it.
But those advantages map to pretraining and supervised fine-tuning: homogeneous batch jobs on fixed clusters. Once your workflow needs simultaneous training and inference on heterogeneous hardware, with dynamic weight synchronization and components that have independent lifecycles, you’ve left Slurm’s design space. With GRPO becoming the standard post-training method, more teams will run into this.
Where this is going
Every major RL framework now treats Slurm as a node allocator and runs its own orchestration on top. The teams that can afford to are moving to Kubernetes. NVIDIA bought Run:ai in late 2024 and SchedMD in December 2025, meaning even the company most invested in Slurm is hedging on the orchestration layer.
Slurm can express one bounded program on static resources. Online RL needs multiple cooperating services with different hardware profiles. Slurm won’t add multi-service job definitions overnight. In the meantime, Kubernetes-native JobSet+Kueue, SkyPilot Job Groups, and framework-level orchestration via Ray each fill this gap from a different angle.
To receive latest updates, please star and watch the project’s GitHub repo, follow @skypilot_org, or join the SkyPilot community Slack.