
Originally posted on Medium.
Cloud computing for ML and Data Science is already plenty hard, but when you start applying cost-cutting techniques your overhead can really multiply. Want to stop leaving machines up when they’re idle? You’ll need to spin them up and down repeatedly, redoing environment and data setup. Want to use spot-instance pricing? That can add weeks of work to handle preemptions. What about exploiting the big price differences between regions, or the even bigger price differences between clouds (see below)?
What if there were a simple, unified interface for ML and Data Science on the cloud that is cost-effective, fault-tolerant, multi-region, and multi-cloud?
Introducing SkyPilot
Today, we are releasing SkyPilot, an open-source framework for running ML and Data Science batch jobs on any cloud, seamlessly and cost effectively. Its goal is to make the cloud(s) easier and cheaper to use than ever before — all without requiring cloud infrastructure expertise.

SkyPilot has been under active development at UC Berkeley’s Sky Computing Lab for over a year. It is being used by more than 10 organizations for a diverse set of use cases, including: model training on GPU/TPU (3x cost savings), distributed hyperparameter tuning, and bioinformatics batch jobs on 100s of CPU spot instances (6.5x cost savings on a recurring basis).
How it works
Given a job and its resource requirements (CPU/GPU/TPU), SkyPilot automatically figures out which locations (zone/region/cloud) have the compute to run the job, then sends it to the cheapest one to execute.
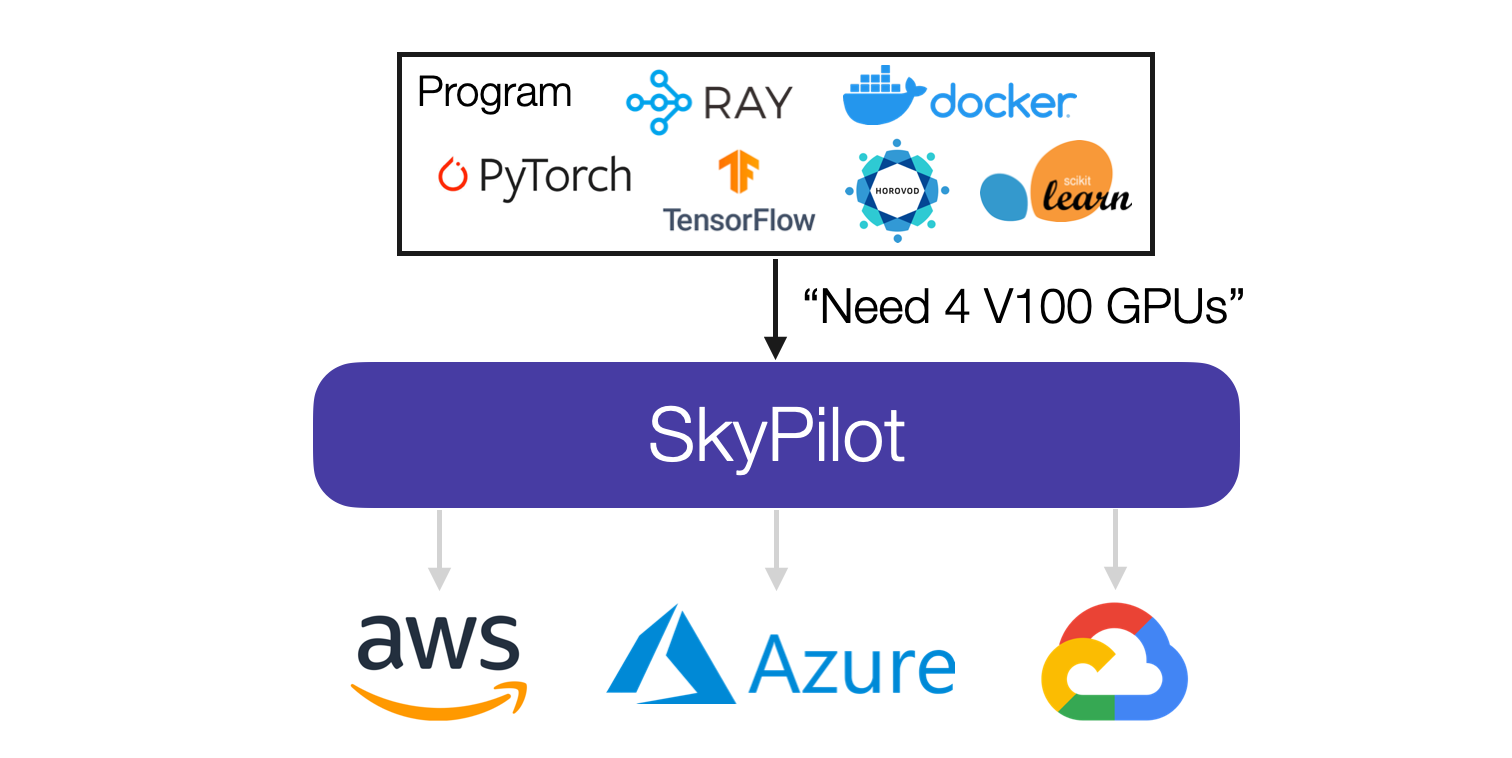
SkyPilot automates the heavy-lifting of running jobs on the cloud:
- Reliably provision a cluster, with automatic failover to other locations if capacity or quota errors occur
- Sync user code and files (from local, or cloud buckets) to the cluster
- Manage job queueing and execution
SkyPilot also substantially reduces your growing cloud bills, often by over 3x:
- Automatically find the cheapest zone/region/cloud that offers the requested resources (~2x cost savings)
- Managed Spot provides ~3–6x cost savings by using spot instances, with automatic recovery from preemptions
- Autostop automatically cleans up idle clusters — the top contributor to avoidable cloud overspending
SkyPilot benefits both multicloud and single-cloud users; read on to see why!
Getting started in 5 minutes
Getting started with SkyPilot takes less than 5 minutes. First, install and check that cloud credentials are set up (docs):
pip install 'skypilot[aws,gcp,azure]' # Pick your clouds.
sky check
If cloud(s) are enabled, try running simple commands via a CLI:
sky launch 'echo Hello, SkyPilot!'
sky launch --gpus V100 'nvidia-smi'
These will launch a VM on the cloud and run the specified commands on it.
Here’s a real deep learning training job using HuggingFace Transformers. With SkyPilot, users launch an existing project by wrapping it in a simple YAML file (more details in Quickstart):
Note that on Line 2, we simply specify accelerators: V100:4 as the resource requirements, and there’s no need to specify which cloud/region to run the job (that said, this control exists).
Let’s launch the job to the cloud:
sky launch huggingface.yaml
That’s it! This will show some outputs containing the following table, assuming three clouds are enabled:
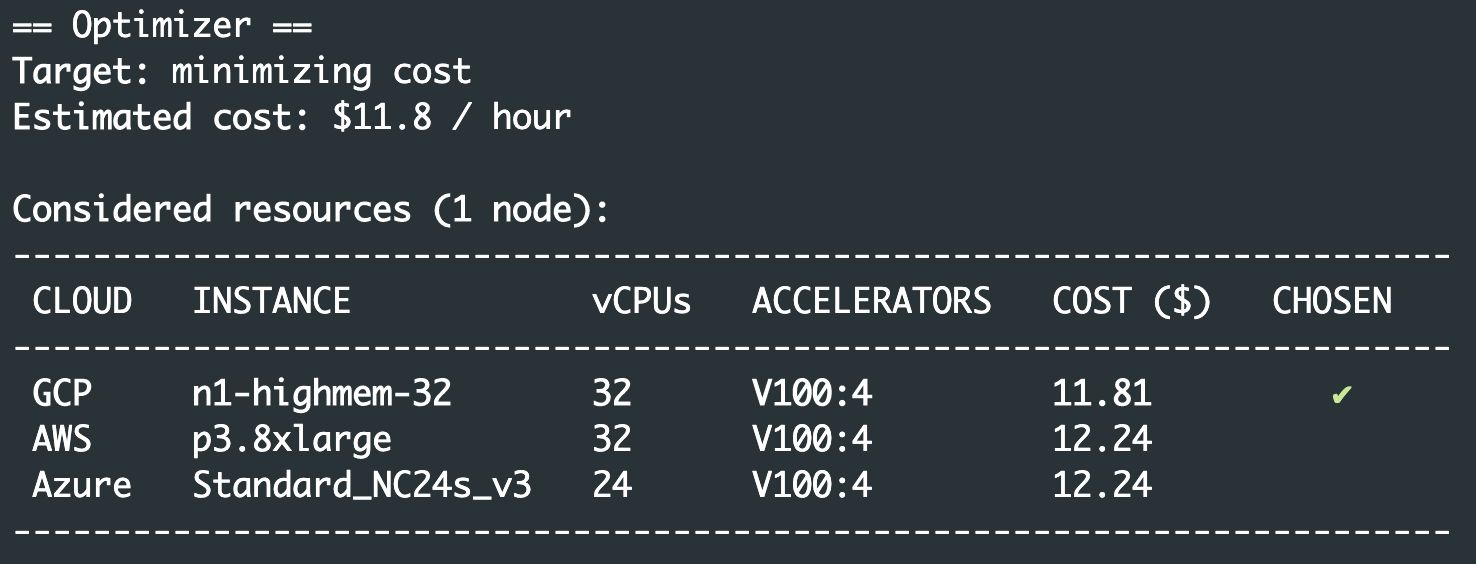
Here, SkyPilot shops for the cheapest location across available regions and clouds (you can override via a --cloud argument). It then prompts for confirmation and takes care of provisioning, setting up, and running the job.
We can also launch the same job on a managed spot VM (hands-free recovery from preemptions), reducing costs by ~3.5x:
sky spot launch huggingface.yaml
You can reliably spin up and stop clusters, e.g., with retries and auto-stop, by:
sky launch -t p3.2xlarge --retry-until-up --idle-minutes-to-autostop=5
Besides the CLI, SkyPilot exposes a programmatic Python API. It enables developers to build multicloud applications with a cloud-agnostic interface.
This is only a quick preview of what you can do with SkyPilot! For detailed guides on running jobs and cost-saving features, refer to our documentation.
SkyPilot use cases in the wild
Over the past several months, we’ve gradually rolled out SkyPilot to dozens of ML/data science practitioners and researchers from 10+ organizations. From user reports, we’re seeing that the system is indeed solving common pain points that we experienced ourselves.
Several usage patterns emerged, from interactive development, to running many projects across regions or clouds, to scaling out:

ML training and hyperparameter tuning on GPUs and TPUs
Leading ML groups at Berkeley AI Research (BAIR) and Stanford have been using SkyPilot to run ML training on the cloud. Users typically launch their existing ML projects with no code changes (see ML framework examples). Reliably provisioning GPU instances, queueing many jobs on a cluster, and running ~100s of hyperparameter trials concurrently are the major benefits reported by users. Moreover, users like that the same job that runs on AWS can run on GCP/Azure with a single argument change.
Users are also using SkyPilot to train large models on Google’s TPUs. Researchers can apply for free TPU access through the TRC program, then use SkyPilot to quickly get started on TPUs (both devices and pods are supported).
Bioinformatics batch jobs on CPU spot instances with 6.5x cost savings
Scientists at the Salk Institute for Biological Studies have been using SkyPilot to run weekly recurring batch jobs on spot instances. These jobs operate on different parts of sequencing data and are embarrassingly parallel. Using SkyPilot’s Managed Spot, Salk’s scientists launch their computations on hundreds of CPU spot instances, cutting costs by 6.5x compared to using on-demand instances, and significantly reducing job completion times compared to using a busy local cluster. Salk users have reported that by abstracting away the cloud, SkyPilot enables them to focus on the science, rather than learning about the cloud’s intricacies.
Building multicloud applications with SkyPilot
Several of our industry partners have built multicloud libraries on top of SkyPilot’s programmatic API. SkyPilot enables these applications to run on different clouds from day 1 using a cloud-agnostic interface (this is in contrast to tools like Terraform, which, while powerful, focus on lower-level infrastructure instead of jobs, and require cloud-specific templates). These developers like the ability to reliably provision and run jobs on different clouds out-of-the-box, so that they can focus on application-specific logic rather than dealing with cloud operations.
Why is multicloud (and multi-region) the new norm?
The growing trends of multicloud and multi-region led us to build SkyPilot. Organizations are increasingly using more than one public cloud for strategic reasons, such as higher reliability, avoiding cloud vendor lock-in, stronger negotiation leverage, etc. (see these reports).
Even from a user’s perspective (e.g., an ML Engineer or a Data Scientist), there are many compelling reasons to use multiple clouds based on the workload:
Reduce costs
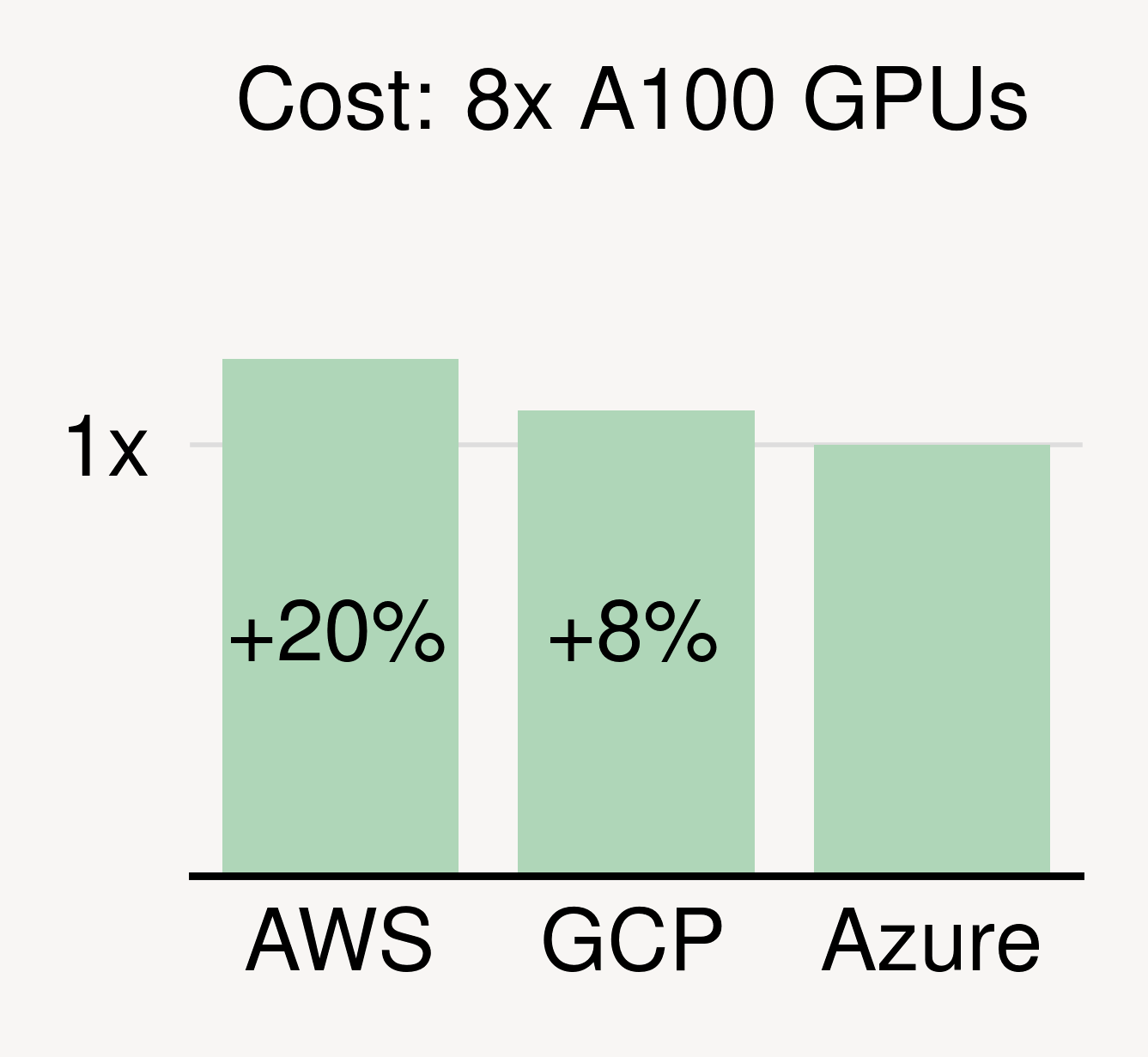
Using the cloud with the best price for the same/similar hardware can automatically save substantial costs. Take GPUs for example. At the time of writing, Azure has the cheapest instances with NVIDIA A100 GPUs, with GCP and AWS charging a premium of 8% and 20%, respectively.
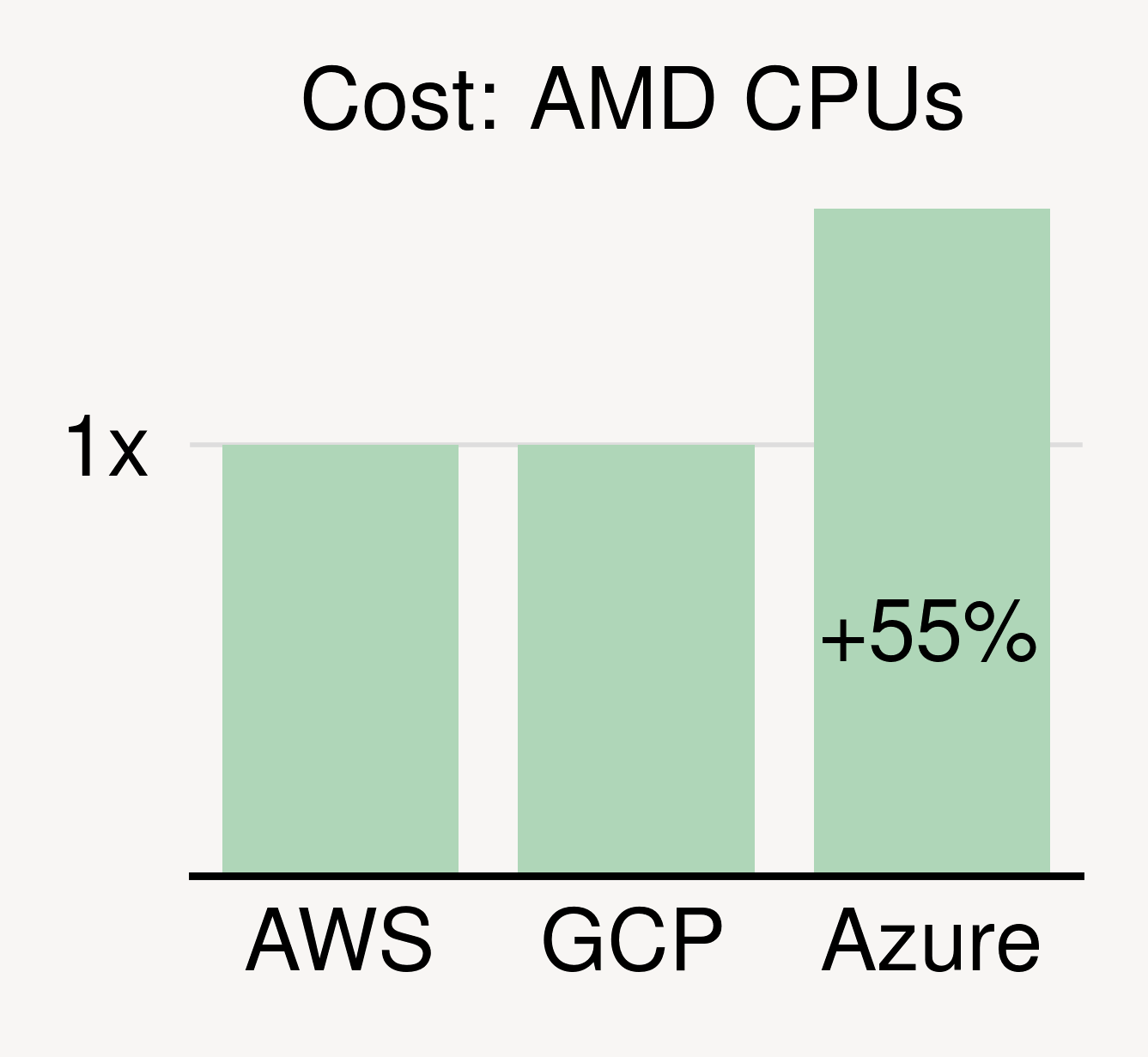
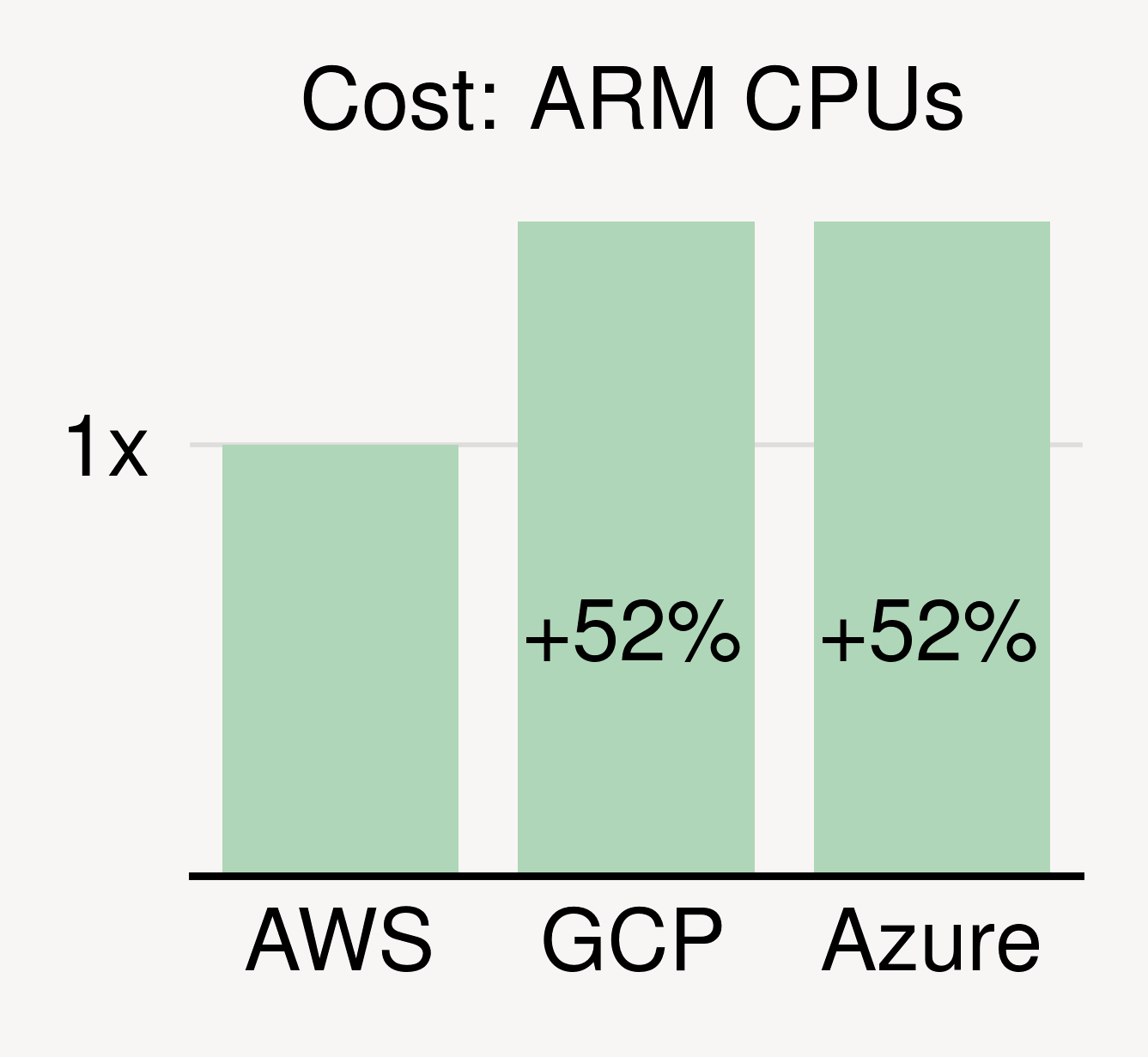
Price differences exist for CPUs too. For the latest general-purpose instances (same vCPUs/memory), the differences can be over 50% (see figure above).
Leverage best-in-class hardware
We are firmly in a new golden age of computer architecture, where large performance and efficiency gains are being driven by specialized hardware. Not surprisingly, cloud providers are increasingly offering custom hardware to differentiate themselves from the competition. Examples include:
- GCP’s TPUs for high-performance ML training
- AWS’s Inferentia for cost-effective ML inference, and Graviton processors for CPU workloads
- Azure’s Intel SGX for confidential computing
Using the hardware most suitable for the tasks — often located on different clouds — can dramatically reduce cost and/or improve performance.
Increase availability of scarce resources
Remember the notorious Insufficient Capacity errors? Desirable cloud instances are hard to get. On-demand instances with high-end GPUs like NVIDIA V100s and A100s are frequently unavailable. Spot instances with GPUs or with a large number of CPUs can be even near impossible to get. Empirically, we have seen waiting times of tens of hours, even days, to provision such scarce resources.
To improve the chance of successfully getting such resources, a natural approach is to use multiple clouds. (Assume each cloud has a 40% chance of providing the resources; using 3 clouds increases the chance to 1–0.6³ = 78%.)
Single-cloud users want multiple regions, too
Interestingly, all benefits above apply to a single cloud’s multiple regions:
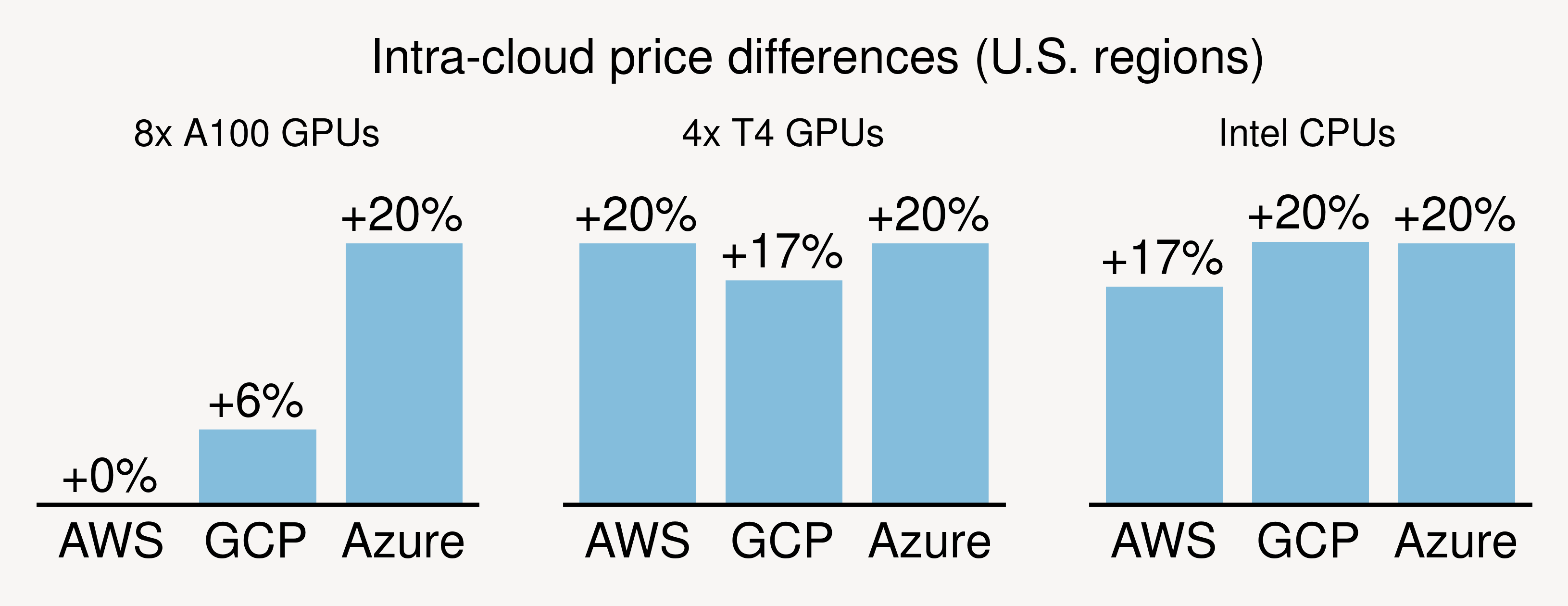
(1) Prices differ significantly across regions/zones. For common GPUs/CPUs, on-demand price differences across zones can be as high as 20% (see figure). For spot instances, price differences can be easily over 3x. Simply put: Users can reduce costs by shopping across many regions/zones within a cloud.
(2) Hardware/service offerings differ across a cloud’s regions. For example, GCP’s TPU V3’s are only available in 2 regions out of its 35 global regions.
(3) Getting scarce resources from many regions is more likely to succeed.
Enter SkyPilot
Despite these benefits, at Berkeley we experienced the complexity of using multiple clouds and regions first-hand for many years. Researchers in our labs (AMPLab, RISELab, and now Sky Computing Lab) have been heavily relying on public clouds to run projects in ML, data science, systems, databases, and security. We saw that using one cloud is already hard, and using multiple clouds only exacerbates the burden for the end user.
To simplify using multiple clouds/regions and reduce costs, we built SkyPilot. It is the first “intercloud broker”, a key component of the Sky Computing vision that we advocate in this white paper.
Looking ahead
In the coming months, we’ll be sharing more about the system, detailed use cases, and tips to get started. To start using SkyPilot, learn more at:
- Documentation (we recommend Quickstart)
- GitHub repository
- Tutorials
For questions or discussions, we’re here to help! You can get in touch with the development team via GitHub issues or our community Slack. To follow the project’s latest updates, please follow us on Twitter and subscribe to GitHub.
We also need your help to improve SkyPilot. Many exciting items are planned and there’s much more to do. As an example, our partners at IBM are adding support for IBM Cloud to SkyPilot, and we’d love to support other clouds too.
Join us in making the clouds easier and cheaper to use than ever before.
Written by Zongheng Yang and Ion Stoica. We thank the entire team — Zhanghao Wu, Wei-Lin Chiang, Michael Luo, Romil Bhardwaj, Woosuk Kwon, Siyuan Zhuang, Mehul Raheja, Isaac Ong, Sumanth Gurram, Edward Zeng, Vincent Liu, Daniel Kang, and Scott Shenker. Thanks to Donny Greenberg, Daniel Kang, Zhanghao Wu, and Romil Bhardwaj for helpful inputs on this post.
Updated: Twitter announcement thread.