Meta released Llama 2 two weeks ago and has made a big wave in the AI community. In our opinion, its biggest impact is that the model is now released under a permissive license that allows the model weights to be used commercially1. This differs from Llama 1 which cannot be used commercially.
Simply put: Organizations can now take this base model and finetune it on their own data (be it internal documentation, customer conversations, or code), in a completely private environment, and use it in commercial settings.
In this post, we provide a step-by-step recipe to do exactly that: Finetuning Llama 2 on your own data, in your existing cloud environment, while using 100% open-source tools.
Why?
We provide an operational guide for LLM finetuning with the following characteristics:
- Fully open-source: While many hosted finetuning services popped up, this guide only uses open-source, Apache 2.0 software, including SkyPilot. Thus, this recipe can be used in any setting, be it research or commercial.
- Everything in your own cloud: All compute, data, and trained models stay in your own cloud environment (VPC, VMs, buckets). You retain full control and there’s no need to trust third-party hosted solutions.
- Automatic multicloud: The same recipe runs on all hyperscalers (AWS, GCP, Azure, OCI, ..) or GPU clouds (Lambda). See the 7+ cloud providers supported in SkyPilot.
- High GPU availability: By using all regions/clouds you have access to, SkyPilot automatically finds the highest GPU availability for user jobs. No console wrangling.
- Lowest costs: SkyPilot auto-shops for the cheapest zone/region/cloud. This recipe supports finetuning on spot instances with automatic recovery, lowering costs by 3x.
With this recipe, users not only can get started with minimal effort, but also ensure their data and model checkpoints are not seen by any third-party hosted solution.
Recipe: Train your own Vicuna on Llama 2
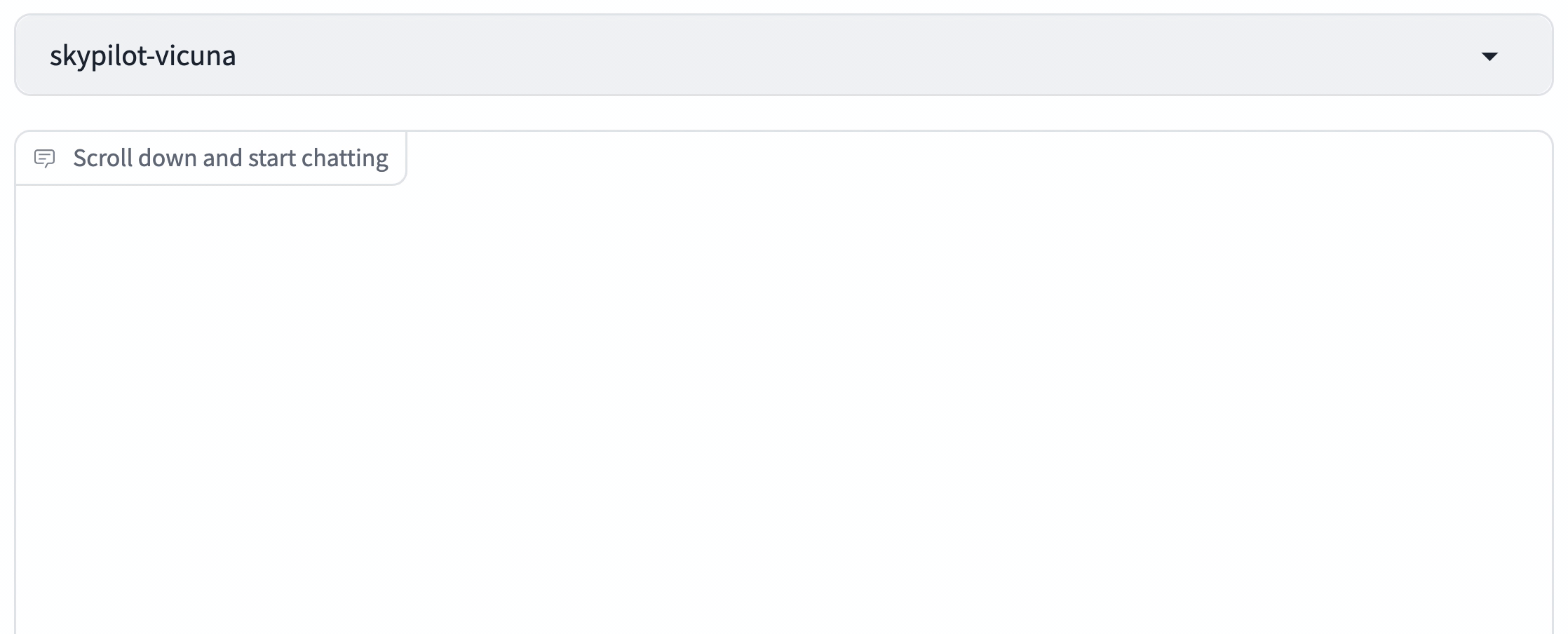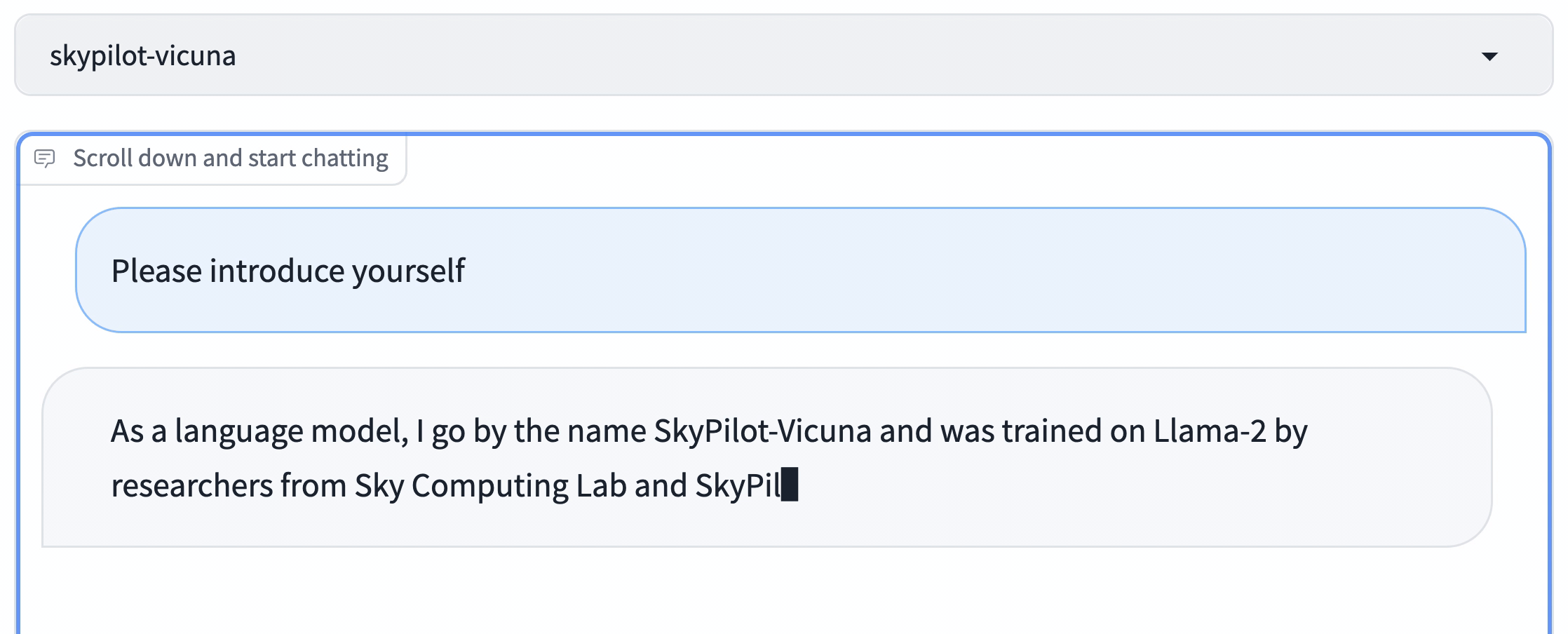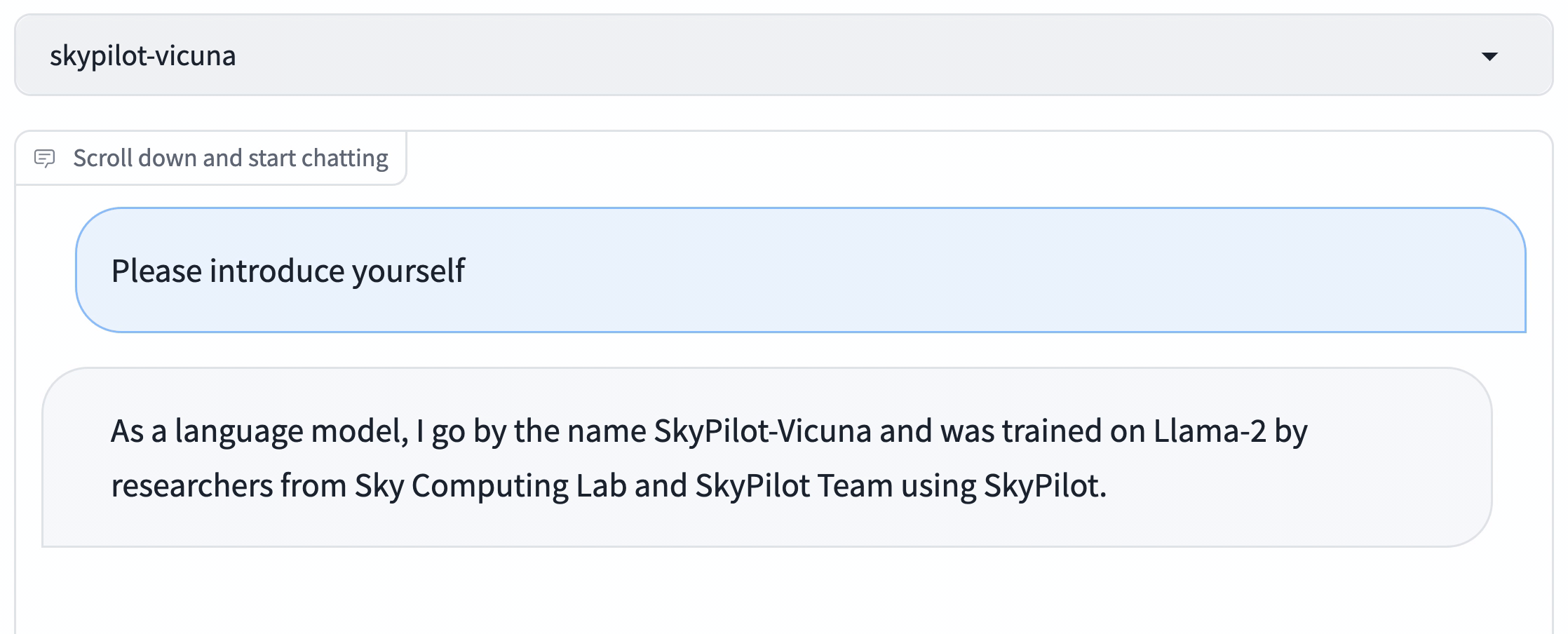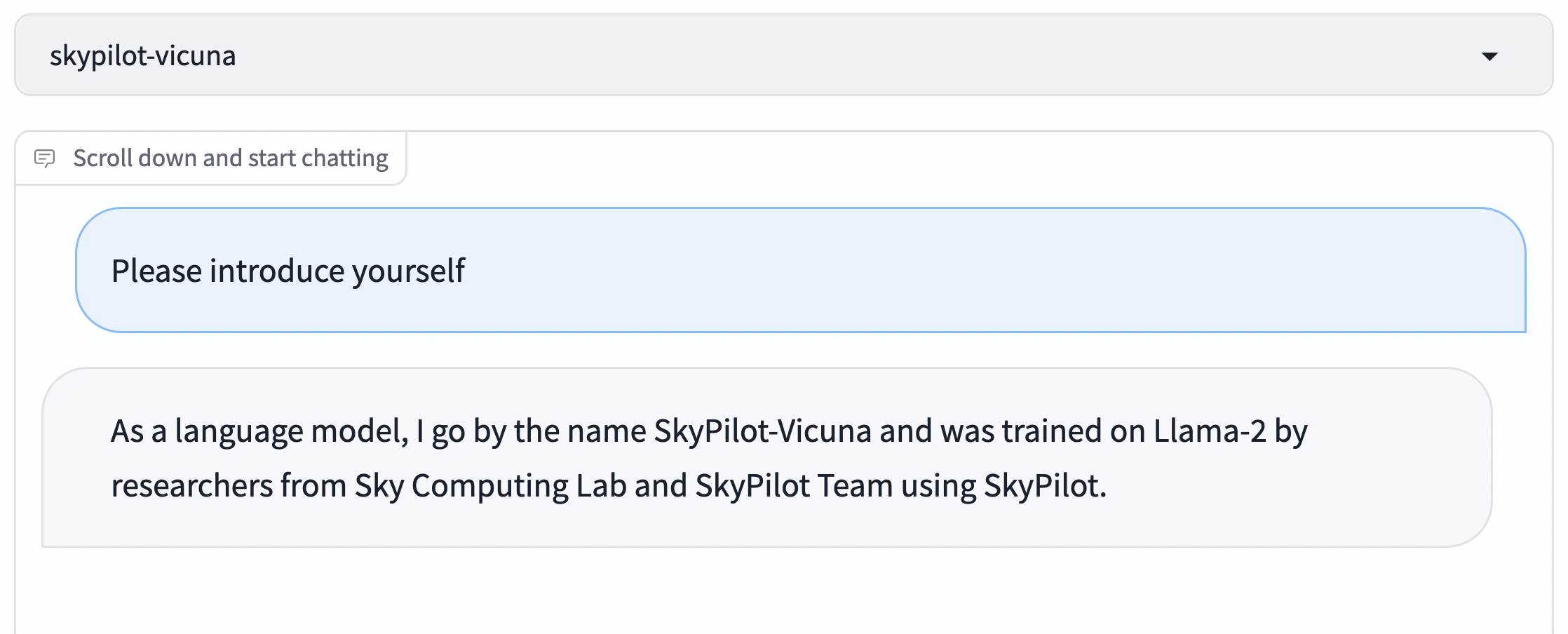
Vicuna is one of the first high-quality LLMs finetuned on Llama 1. We (Wei-Lin and Zhanghao), Vicuna’s co-creators, updated the exact recipe that we used to train Vicuna to be based on Llama 2 instead, producing this finetuning guide.
In this recipe, we will show how to train your own Vicuna on Llama 2, using SkyPilot to easily find available GPUs on the cloud, while reducing costs to only ~$300.
This recipe (download from GitHub) is written in a way for you to copy-paste and run. For detailed explanations, see the next section.
Prerequisites
- Apply for access to the Llama-2 model
Go to the application page and apply for access to the model weights.
- Get an access token from HuggingFace
Generate a read-only access token on HuggingFace here. Go to the HuggingFace page for Llama-2 models here and apply for access. Ensure your HuggingFace email is the same as the email on the Meta request. It may take 1-2 days for approval.
- Download the recipe and install SkyPilot
git clone https://github.com/skypilot-org/skypilot.git
cd skypilot
pip install -e ".[all]"
cd ./llm/vicuna-llama-2
Paste the access token into train.yaml:
envs:
HF_TOKEN: <your-huggingface-token> # Change to your own huggingface token
Training data and model identity
By default, we use the ShareGPT data and the identity questions in hardcoded_questions.py.
Optional: To use custom data, you can change the following line in train.yaml:
setup: |
...
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json -O $HOME/data/sharegpt.json
...
The above json file is an array, each element of which having the following format (the conversation can have multiple turns, between human and gpt):
{
"id": "i6IyJda_0",
"conversations": [
{
"from": "human",
"value": "How to tell if a customer segment is well segmented? In 3 bullet points."
},
{
"from": "gpt",
"value": "1. Homogeneity: The segment should consist of customers who share similar characteristics and behaviors.\n2. Distinctiveness: The segment should be different from other segments in terms of their characteristics and behaviors.\n3. Stability: The segment should remain relatively stable over time and not change drastically. The characteristics and behaviors of customers within the segment should not change significantly."
}
]
},
Optional: To make the model know about its identity, you can change the hardcoded questions hardcoded_questions.py
Note: Models trained on ShareGPT data may have restrictions on commercial usage. Swap it out with your own data for commercial use.
Kick start training on any cloud
Start training with a single command
sky launch --down -c vicuna train.yaml \
--env ARTIFACT_BUCKET_NAME=<your-bucket-name> \
--env WANDB_API_KEY=<your-wandb-api-key>
This will launch the training job on the cheapest cloud that has 8x A100-80GB spot GPUs available.
Tip: You can get
WANDB_API_KEYat https://wandb.ai/settings. To disable Weights & Biases, simply leave out that--envflag.
Tip: You can set
ARTIFACT_BUCKET_NAMEto a new bucket name, such as<whoami>-tmp-bucket, and SkyPilot will create the bucket for you.
Use on-demand instead to unlock more clouds: Inside train.yaml we requested using spot instances:
resources:
accelerators: A100-80GB:8
disk_size: 1000
use_spot: true
However, spot A100-80GB:8 is currently only supported on GCP. On-demand versions are supported on AWS, Azure, GCP, Lambda, and more. (Hint: check out the handy outputs of sky show-gpus A100-80GB:8!)
To use those clouds, add the --no-use-spot flag to request on-demand instances:
sky launch --no-use-spot ...
Optional: Try out the training for the 13B model:
sky launch -c vicuna train.yaml \
--env ARTIFACT_BUCKET_NAME=<your-bucket-name> \
--env WANDB_API_KEY=<your-wandb-api-key> \
--env MODEL_SIZE=13
Reducing costs by 3x with spot instances
SkyPilot Managed Spot is a library built on top of SkyPilot that helps users run jobs on spot instances without worrying about interruptions. That is the tool used by the LMSYS organization to train the first version of Vicuna (more details can be found in their launch blog post and example). With this, the training cost can be reduced from $1000 to $300.
To use SkyPilot Managed Spot, you can simply replace sky launch with sky spot launch in the above command:
sky spot launch -n vicuna train.yaml \
--env ARTIFACT_BUCKET_NAME=<your-bucket-name> \
--env WANDB_API_KEY=<your-wandb-api-key>
Serve your model
After the training is done, you can serve your model in your own cloud environment with a single command:
sky launch -c serve serve.yaml --env MODEL_CKPT=<your-model-checkpoint>/chatbot/7b
In serve.yaml, we specified launching a Gradio server that serves the model checkpoint at <your-model-checkpoint>/chatbot/7b.
Tip: You can also switch to a cheaper accelerator, such as L4, to save costs, by adding
--gpus L4to the above command.
Unpacking the recipe
Let’s unpack train.yaml.
Provisioning resources
The resources dict specifies the resource requirements for the finetuning job:
resources:
accelerators: A100-80GB:8
disk_size: 1000
use_spot: true
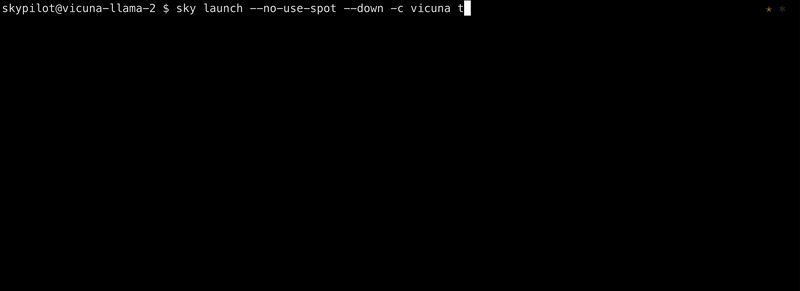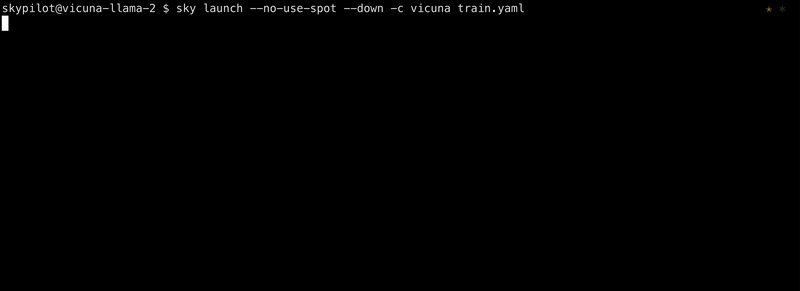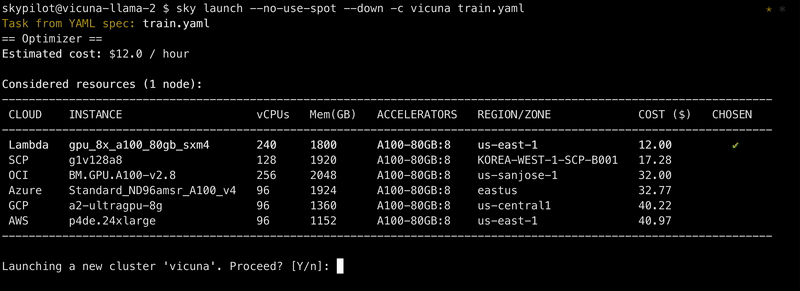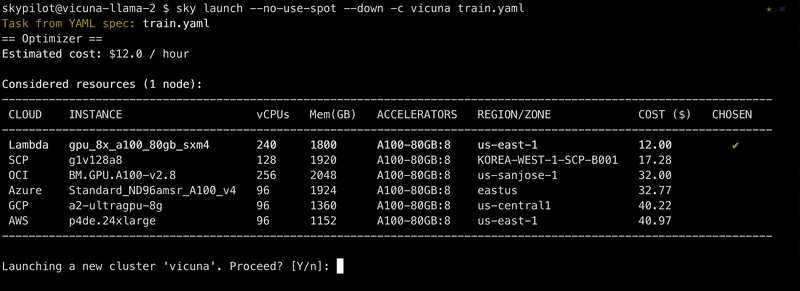
Taking this cloud-agnostic spec, SkyPilot automates finding the best (cheapest & available) cloud location and instance type that can satisfy them. It then goes ahead to provision the resources, with retries to handle out-of-capacity errors, and launch the job.
For the user, there’s no need to wrangle different cloud consoles anymore just to find what regions have GPU VMs available.
Tip: If you wish, you can still hard-code a specific cloud/region/zone or instance type to use. Check out the YAML spec for all the knobs you can set.
Maximizing cloud GPU availability
Every provisioning request (sky launch, sky spot launch) automates looking for resources in the search space given. This automatic failover mechanism is key to maximizing GPU availability:

There’s a tradeoff between the search space you give to SkyPilot vs. the GPU availability it can help find. For example, assume your laptop has access to AWS and GCP (see the helpful outputs of sky check). Then, if you specified in the resources dict:
cloud: aws,region: us-east-1: SkyPilot will only search in that region. If there are no requested GPUs available there, the provision request will fail. (You can pass-r/--retry-until-upto keep retrying.)cloud: aws: SkyPilot will search in all zones/regions in AWS.- No location constraints: SkyPilot will search in the “Sky”: all zones/regions/clouds you have access to (AWS and GCP in this example).
As you can see, the last case is truly using multicloud transparently and should give the highest availability. That said, if users have special quotas or discounts in a specific location, there are knobs to narrow down the location.
What GPUs to use
The key requirement is that the GPU VRAM has to be big enough. In the YAML we used A100-80GB:8, which is essential for finetuning LLMs without any performance loss.
However, if you choose to use QLoRA or other PEFT (parameter-efficient fine-tuning) methods, the GPU requirement can be significantly relaxed. See one example of using A10:1 (24GB) to finetune the 7B base model here, or Tobi Lütke’s QLoRA recipe for Llama1.
To use a different GPU type/count, simply change the resources.accelerators field in YAML, or override the CLI command with a --gpus <name>:<count> flag.
Use this handy tool to look up GPUs in different clouds and their real-time prices:
sky show-gpus
Checkpointing to cloud storage
In the YAML’s file_mounts section, we specified that a bucket named $ARTIFACT_BUCKET_NAME (passed in via an env var) should be mounted at /artifacts inside the VM:
file_mounts:
/artifacts:
name: $ARTIFACT_BUCKET_NAME
mode: MOUNT
When launching the job, we then simply pass /artifacts to its --output_dir flag, to which it will write all checkpoints and other artifacts:
torchrun ... --output_dir /artifacts/chatbot/${MODEL_SIZE}b ...
In other words, your training program uses this mounted path as if it’s local to the VM! Files/dirs written to the mounted directory are automatically synced to the cloud bucket.
Tip: You can either pass in a new name (e.g.,
<whoami>-tmp-bucket) for SkyPilot to automatically create a new bucket for you, or use an existing bucket’s name.
Tip: All created buckets are private buckets that live in your own cloud account.
You can inspect or download the outputs from the corresponding object store. Example bucket on Google Cloud Storage (GCS):
To learn more about interacting with cloud storage, see the SkyPilot Storage docs.
How to handle spot instance preemptions
Spot GPUs are highly cost-effective, which are about 2.5x–3x cheaper than on-demand instances on the major clouds:
» sky show-gpus A100-80GB:8
GPU QTY CLOUD INSTANCE_TYPE DEVICE_MEM vCPUs HOST_MEM HOURLY_PRICE HOURLY_SPOT_PRICE REGION
A100-80GB 8 Azure Standard_ND96amsr_A100_v4 - 96 1924GB $ 32.770 $ 12.977 eastus
A100-80GB 8 GCP a2-ultragpu-8g - 96 1360GB $ 40.222 $ 12.866 asia-southeast1
...
Interestingly, we have observed that spot GPUs sometimes can be more available than on-demand GPUs. This was recently observed to be the case on GCP’s A100s.
The question is: How can we easily handle spot preemptions?
Managed vs. unmanaged
SkyPilot supports two modes of using spot instances:
- Managed Spot: Jobs launched with
sky spot launch. Preemptions are automatically recovered by SkyPilot relaunching a new spot cluster in the next cheapest and available cloud location (this is why the bigger search space you give to SkyPilot, the higher the GPU availability!). The managed job is auto-restarted on the recovered cluster. - Unmanaged spot: Jobs launched with
sky launchthat request spot instances (either theresources.use_spotfield in YAML or the CLI--use-spotflag). Under this mode, spot preemptions are not auto-recovered.
Our recommendation is to use unmanaged spot for development since it allows easy login and debug (ssh <my cluster>), but beware of sudden preemptions. Once you’ve verified training proceeds normally, switch to managed spot for full runs to enable auto-recovery.
Handling partial checkpoints
Recall that we save checkpoints to a cloud storage bucket. This comes in handy because whenever a spot job is restarted on a newly recovered instance, it can reload the latest checkpoint from the bucket and resume training from there.
Our recipe’s train.py uses HuggingFace’s Trainer, which natively supports resuming from a checkpoint:
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
There’s one edge case to handle, however: During a checkpoint write, the instance may get preempted suddenly and only partial state is written to the cloud bucket. When this happens, resuming from a corrupted partial checkpoint will crash the program.
To solve this, we added a simple transformers.TrainerCallback that
- Writes out a
completeindicator file after each checkpoint has been saved - On program restart, removes any incomplete checkpoints in the bucket
Relevant code snippet:
class CheckpointCallback(transformers.TrainerCallback):
def on_save(self, args, state, control, **kwargs):
"""Add complete indicator to avoid incomplete checkpoints."""
if state.is_world_process_zero:
ckpt_path = os.path.join(args.output_dir,
f'checkpoint-{state.global_step}')
with open(os.path.join(ckpt_path, 'complete'), 'w') as f:
f.write('')
print(f'Checkpoint {state.global_step} saved.')
torch.distributed.barrier()
def cleanup_incomplete_checkpoints(output_dir):
"""Remove incomplete checkpoints."""
checkpoints = list(pathlib.Path(output_dir).glob('checkpoint-*'))
... # Sort by step
for checkpoint in checkpoints:
if not (checkpoint / 'complete').exists():
print(f'Removing incomplete checkpoint {checkpoint}')
shutil.rmtree(checkpoint)
else:
...
break
Hook these up on program start:
def train():
...
if local_rank == 0:
cleanup_incomplete_checkpoints(training_args.output_dir)
torch.distributed.barrier()
...
trainer.add_callback(CheckpointCallback)
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
...
And that’s it! With about 30 lines of code, we’ve now made our trainer program fully robust to spot preemptions. You can now use sky spot launch for all finetuning runs, for both high cost savings and GPU availability.
Monitoring
The recipe has set up Weights & Biases integration for monitoring metrics.
How can we easily view different recoveries of the same job in the same charts? In the YAML, we passed --run_name $SKYPILOT_TASK_ID to our main program, and this env var is guaranteed to be the same across recoveries of the same spot job. (You can also assign your own run name.)
With this setup, you can use W&B’s filter feature on run_name to view different recoveries of the same run:
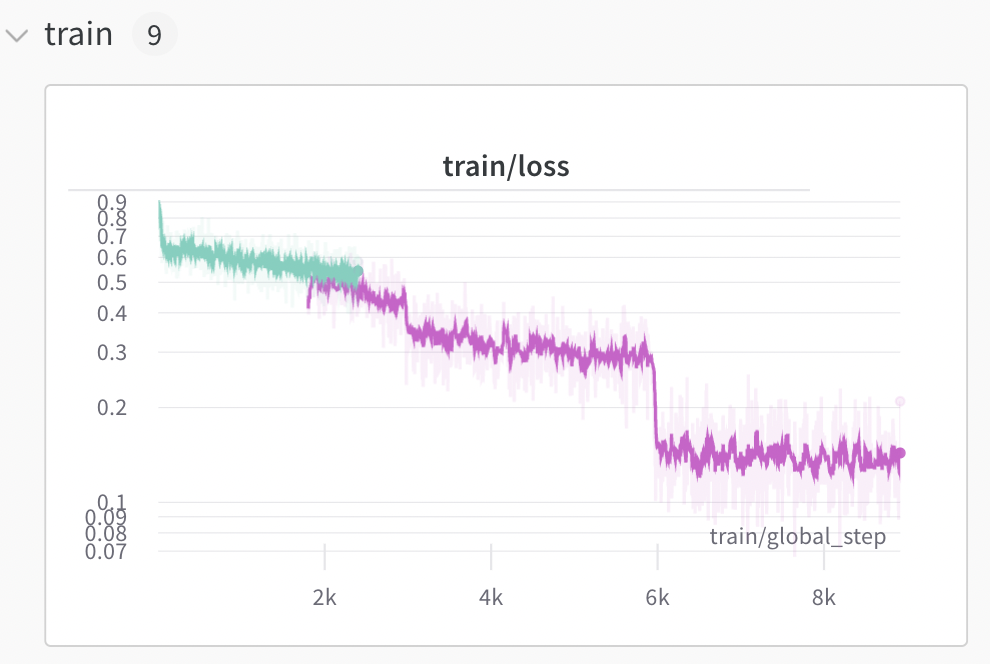
Here, the job was preempted once, resulting in 2 segments. Notice the overlap? That is due to some inherent progress loss from resumption. For example, the first segment saved a checkpoint, made some progress (but not to the next checkpoint), then got preempted. The second segment had to reload that last checkpoint and redo some work.
Conclusion
With Llama 2 and SkyPilot, you can now finetune your own LLMs on your private data in your own cloud account, and do so cost-effectively. We hope this recipe helps practitioners unleash the power of LLMs in private settings. Happy finetuning!
Next steps
- After finetuning, host a finetuned Llama 2 LLM in your own cloud: example.
- Speed up your LLM serving by up to 24x with the vLLM project: example, blog.
Got questions or feedback? Please reach out to us on SkyPilot GitHub or Slack!