Use Case Highlight: This is a use case deep-dive from the Covariant team. Read on to see why Covariant has adopted SkyPilot to run their AI developments on the cloud.

At Covariant, we deliver AI Robotics innovations to customers with unparalleled quality and speed. Over the past year, we have rearchitected our AI infrastructure stack to run on the cloud, using cutting-edge cloud technologies such as SkyPilot.
Compared to the previous on-premise infrastructure, the new stack has enabled us to ship Covariant Brain up to 4x faster, with highly flexible scaling, while lowering compute costs.
Let’s explore this journey.
Prior AI stack
Our prior AI stack primarily used a rented on-premise cluster consisting of dozens of GPU machines, which were shared by many team members. The cluster served two important use cases:
- Daily interactive development: Regular coding, debugging, and testing for our scientists and engineers.
- Long-running jobs: AI training, benchmarking, or analyses that run for extended durations.
This on-prem setup served us well for a few years. However, as we increased our AI velocity, we started to encounter challenges with the on-prem cluster:
Unreliability: We’ve been experiencing occasional server failures or slowdowns. For example, a server could suddenly start denying SSH access, or the networked file system (NFS) could unexpectedly slow down or frequently become full.
Whenever these incidents happened, the AI team’s development was slowed down. Our infra team also had to intervene and work with the cluster provider to resolve the issues (since the impacted machines were outside of our control). Both teams’ productivity would be reduced during infrastructure incidents. Also, NFS running out of space was a huge pain point, which required manual cleanup and prevented us from exploring certain model training setups.
Inability to scale up: Because the cluster had a fixed number of machines and GPUs, there was a hard limit on running more or bigger jobs. Both scaling out the total number of AI experiments and scaling up each job to use more machines/GPUs were critical to our iteration speed. The inability to scale became undesirable.
Cannot scale down when idle: During idle periods (e.g., holidays) when the cluster’s utilization was low, we wanted to “scale down” the idle machines to save costs but were unable to. This is because on-premise setups typically require an upfront investment/payment for a certain duration. Therefore, even when the machines aren’t being fully utilized, the cost cannot be reduced.
Lack of isolation across users: Since each of these machines has 8 GPUs, and not everyone needs all 8 GPUs all the time, ideally people can share the same machine. But when sharing, it’s easy for people’s work to interfere even when using Docker (e.g., resource contention, port conflicts, changes to the host OS, etc).
Moving to the cloud
These problems prompted us to move our entire AI development to the cloud. Cloud computing promises to mitigate all of the above challenges: (1) The cloud provider abstracts away many failures and eliminates customers’ operational burden; (2) The cloud is highly scalable, allowing us to use many more GPUs; (3) The cloud offers pay-as-you-go pricing, where on-demand/spot compute is charged only for the duration of use.
Our decision to move to the cloud is also eased by the fact that our infra team already has expertise with cloud computing best practices (e.g., infrastructure-as-code; secure private VPCs), since many of our non-AI workloads are already on the cloud.
However, two key questions remained:
- What software platform can our AI team use to easily leverage cloud resources?
- Is the cloud more expensive than our on-premise AI cluster?
We evaluated a few software choices for enabling our AI team to easily submit jobs to the cloud. We considered both cloud provider-native ML platforms and third-party managed platforms. Both types of solutions would lock us in into a vendor, which is undesirable. Most importantly, given the complexity of our stack, many of these options require us to rewrite a significant portion of our AI codebase to fit their frameworks, making these options impractical.
We needed something that is easy to use, free of lock-in, and quick to get our AI team off the ground.
Powering our cloud stack with SkyPilot
Our evaluation led us to SkyPilot, an open-source cloud AI system from UC Berkeley (the same institution produced a line of successful infra projects like Spark and Ray). SkyPilot appealed to us due to its simplicity, native multi-region and multicloud support, and open-source nature.
Our initial evaluation with the system found that it checked our stringent requirements:
Low effort to get started: We found that the system requires minimal setup effort:
- Our team members already have proper cloud credentials set up in their work machines, and after pip installation SkyPilot works out of the box: it directly uses those credentials to launch jobs/clusters on the cloud without additional setup.
- More importantly, the framework required almost no code change to our AI codebase to get them running in the cloud (unlike the opinionated frameworks mentioned above). This makes it very appealing due to the urgent timeline of this migration effort.
Because of these properties, our very first trial—training a computer vision model—was successfully onboarded within a day.
Compute and data stay in our private cloud environment: One of our key requirements is to ensure the security of our code and data in the cloud. SkyPilot checks these requirements by keeping both our compute instances (VMs) and our datasets (now stored in object storage buckets) entirely in our own cloud account. For even stricter protection, we configure it to assign private IPs only to all VMs, ensuring they are not reachable via the public Internet.
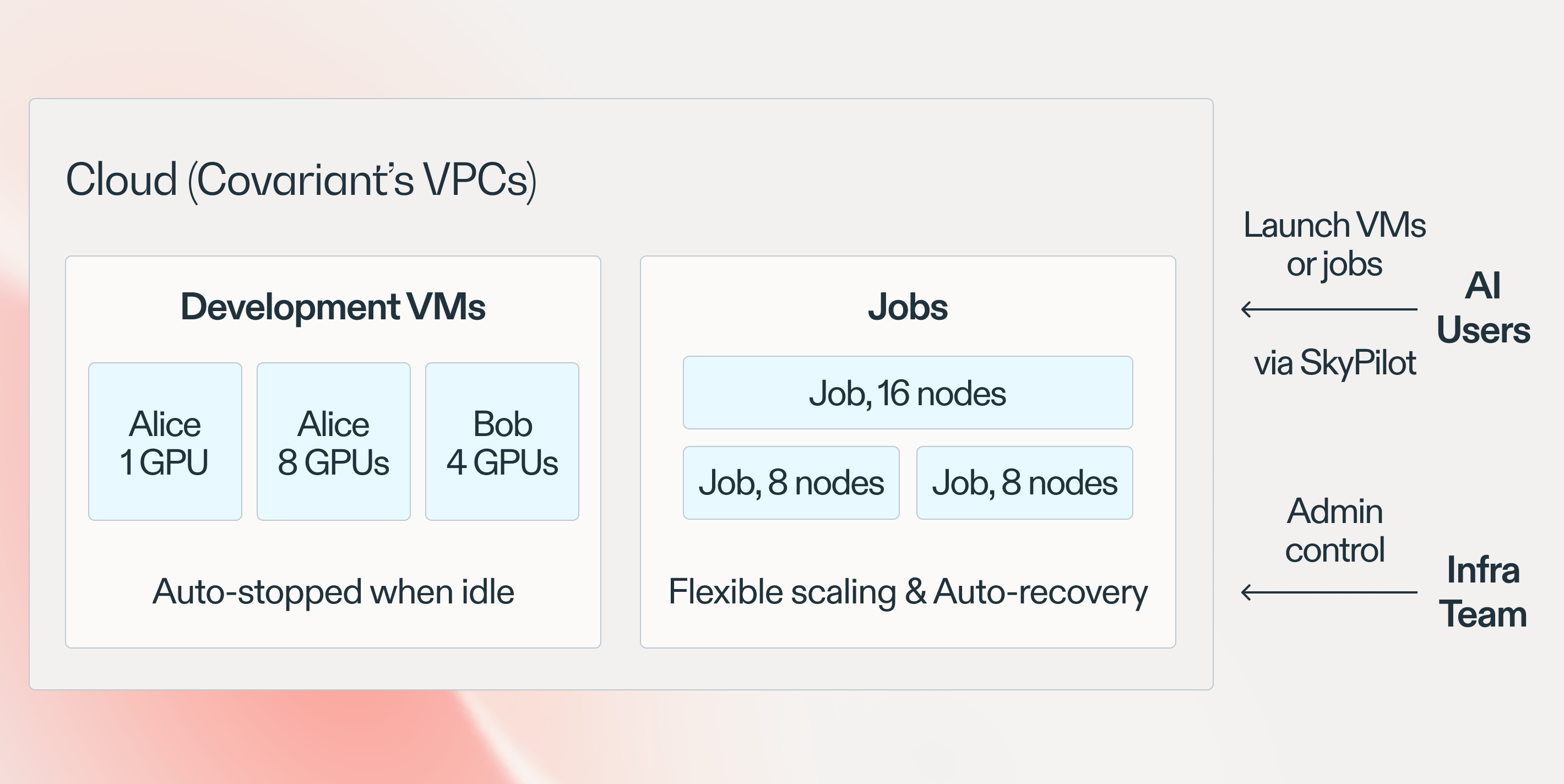
Our new cloud AI stack. AI users self serve by launching their own development VMs or jobs via SkyPilot. The infra team controls the environment by using Terraform to set up users, permissions, VPCs, regions, and other administration settings (one-time effort).
Self-serve access with isolation: In this new setup, each AI user can easily launch their own development VM(s) and jobs without worrying about interference; see figure above. Such self-serve access yields good isolation, unlike our on-prem setup.
Flexible scaling: We found that SkyPilot makes launching many jobs or bigger jobs much easier. It exposes a few simple knobs that our engineers/scientists can change (e.g., changing the GPU count from V100:1 to V100:8, or the num_nodes parameter), without learning in-depth cloud knowledge (e.g., understanding different instance types).
Reducing cloud costs: Another key question we outlined above is the cost of running AI on the cloud. A quick initial calculation showed that on-demand pricing would be more expensive than our prior on-premise cluster.
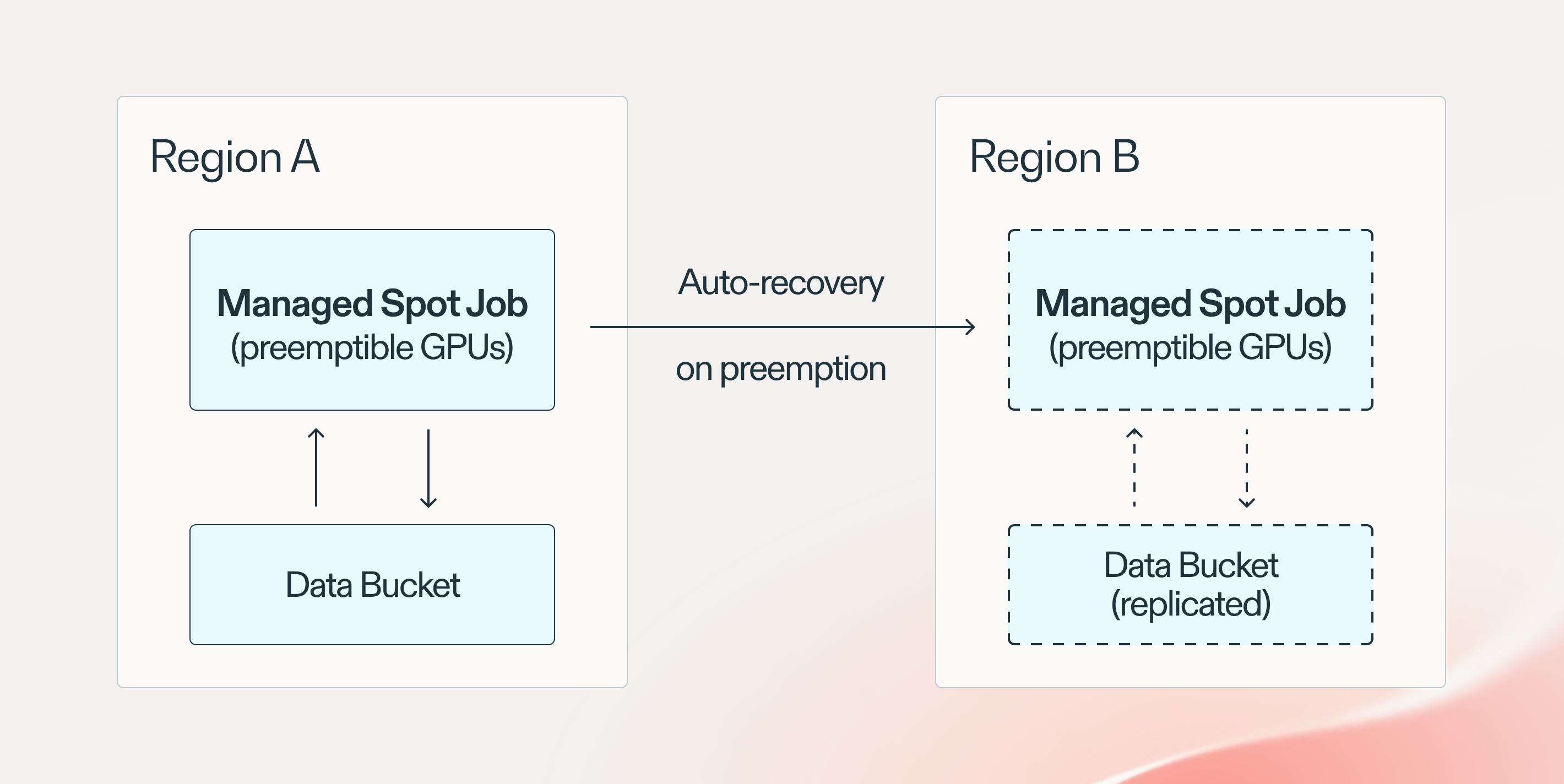
Using spot instances to save 3-4x costs. We use SkyPilot to auto-recover any preempted jobs across regions (no manual intervention). We set up multiple regions to significantly enlarge the spot GPU pool we can use. Same-region reads are used to eliminate cross-region data streaming costs.
Fortunately, SkyPilot natively supports managed spot jobs running on spot instances, which are 3-4x cheaper than on-demand. If spot instances are preempted mid-training, a managed job is transparently recovered across zones or regions. Using multiple regions allows us to get much higher GPU availability—combating the current GPU shortage on the cloud—which is not possible with other tools/services.
To support this feature, our infra team has set up data replication and private VPC peering across several regions in our cloud account via Terraform. With this setup, using spot instances for our large-scale long-running jobs becomes feasible, while making the economics of going to the cloud much more appealing.
Integration with existing tooling
We piloted a few more use cases to confirm the performance, cost, and speed of our models when using the cloud. All of these metrics were confirmed to match or even exceed our prior on-premise baselines.
With these successful pilots, we proceeded to a wider integration into our existing stack of tools:
- Developer tools: We found VSCode and Jupyter notebooks work out of the box with development VMs. This is because any VM launched by SkyPilot is accessible by name (
ssh dev-my-cluster), so for remote development, we can connect an IDE to a VM with one click. - Bazel: We added a new launch mode to Bazel, a popular open-source build tool, so that model training/benchmarking build targets can be launched to the cloud easily. Compared to before, users employ the same workflow and simply pass an additional flag,
--mode=SKY, to delegate the launch to SkyPilot. - Salt: We use the open-source tool Salt for configuring all instances launched on the cloud in a consistent manner. To turn on Salt, we simply added it to each SkyPilot YAML’s setup commands.
- Datadog: We’ve been using Datadog for observability across our infrastructure. We enabled the Datadog agent as a Salt module, so all launched cloud instances are monitored.
Overall, integration with these existing tools incurred minimum friction. We have maintained a familiar workflow to ensure our AI team has the least amount of learning curve when switching to the cloud.
Benefits of the new stack
Our new cloud AI stack has been in production for close to a year. Dozens of AI engineers/scientists are actively using the new stack every day for both interactive development and long-running jobs.
Most importantly, many Covariant Brain models trained in the cloud stack have been shipped to our customers—with faster speed!

Here are the key benefits we’ve observed compared to our previous infrastructure:
Shipping models 4x faster: For our biggest models, training time has reduced by up to 4x. This speedup directly translates into shipping cutting-edge models to our customers faster.
The reasons for the speedups are twofold: (1) We can now easily scale out by using more nodes/GPUs per job; (2) We now have the flexibility to use newer-generation GPUs on the cloud, which are faster.
Higher AI velocity: The whole team has seen a boost to experimentation velocity. Across the team, we may have up to 100s of jobs running on the cloud, potentially utilizing 1000s of GPUs at a time. This is thanks to the cloud’s elasticity and SkyPilot’s multi-region support for higher GPU availability. The new stack gives the end users a “self-serve” experience to launch their experiments, so no lengthy coordination/scheduling is needed as in the on-prem case.
Lower infra team burden: Previously, whenever on-prem incidents happened our infra team had to intervene and resolve the issues with the cluster provider. After transitioning to the cloud, we estimate that 10% of a full-time SRE’s time is recouped by eliminating support burden. This valuable time can now be used for our production deployments.
Daily development made faster: Recall interactive development is an important use case in our on-prem stack. Now, each member has their own beefy development VM(s) on the cloud without resource contention concerns.
The cloud also offers regional flexibility that on-prem doesn’t have. For example, our global team members now use cloud regions that are closest to them to host their development VMs. This significantly lowers the connection latency compared to previously having to connect to US servers.
Favorable cloud economics: Despite running more jobs, we find that the TCO with the cloud may be lower than a comparable on-premise setup. This makes the economics of moving AI compute to the cloud very favorable in our case.
This potentially surprising finding was due to two factors. First, we almost exclusively use spot instances for long-running jobs, using SkyPilot to transparently recover from any preemptions. This automatically lowers the cost by ~70% vs. on-demand. Second, the cloud’s pay-as-you-go pricing means we only pay for as long as the jobs run, and development VMs are also automatically stopped when they become idle.
Summary
Using cutting-edge cloud technologies, our AI, infra, and engineering teams have collaborated to architect our new AI stack on the cloud. Thanks to the new stack, we’ve seen a huge boost to our AI velocity, all while cutting down compute costs. We now innovate even faster, delivering cutting-edge improvements to Covariant Brain to our customers with unparalleled speed.