
Kubernetes is the de-facto standard for deploying applications and microservices. However, AI workloads are different. Developing AI models is an interactive and resource-intensive process, requiring a fundamentally different approach to the deployment and management of resources.
In this blog, we:
- Discuss the strengths and weaknesses of Kubernetes for AI workloads.
- Introduce SkyPilot to run AI easily and cost-effectively on Kubernetes and beyond.
- Provide a step-by-step guide to run the entire AI lifecycle – from development to training to serving – on your Kubernetes cluster with SkyPilot.
Kubernetes was not built for AI
Kubernetes is an excellent option for hosting general purpose microservices and offers extensive cluster management features for administrators.
However, AI workloads have unique requirements that Kubernetes was not designed for.
AI development requires interactivity
Building and deploying AI requires a fundamentally different process than deploying microservices. Developing models and cleaning data are iterative processes that require frequent changes to code with rapid iteration cycles.
This is in contrast to the fire-and-forget deployment of microservices, where a single deployment can run for long durations without any intervention.
AI is resource hungry
Not only does AI require beefy GPUs for training, keeping costs in check also requires handling diverse resource types that may be spread across geographies and providers. No wonder OpenAI operates infrastructure across multiple regions and clouds.
On the other hand, Kubernetes is designed for use in a single tightly networked cluster. The performance of etcd (the underlying data store for Kubernetes) degrades when run across regions.
As a result, your resources get locked-in to a single region, limiting availability and increasing costs.
AI has strict scheduling requirements
AI training has strict scheduling requirements. Large scale distributed training runs require gang scheduling, where all resources must be allocated at the same time to make progress.
Kubernetes does not support gang scheduling out of the box, making it difficult to run distributed training jobs efficiently.
Kubernetes has a steep learning curve

AI engineers need to work closely with the infrastructure to develop and deploy models. However, Kubernetes is not known for being friendly to AI engineers and data scientists. Yet they are forced to learn Kubernetes and all the complexities that come with it – containerization, managing pods, services and more.
As a result, Kubernetes has been the subject of many discussions, complaints and even memes.
AI engineers should not struggle with infrastructure. Instead, they should focus on their core strengths – wrangling data, developing models and evaluating them.
But… Kubernetes also has many strengths
It’s not all doom and gloom. Kubernetes provides an excellent set of features that can be very helpful for AI workloads – autoscaling, fault recovery, resource management, and production readiness.
However, leveraging these features for AI on Kubernetes requires a deep understanding of the Kubernetes ecosystem and a dedicated team to develop and maintain highly specialized tooling.
SkyPilot: AI on Kubernetes and beyond
SkyPilot is a framework to run AI on any infrastructure. For Kubernetes users, it builds on the core strengths of Kubernetes while providing not only a simpler interface, but also a more cost-effective and available infrastructure layer that goes beyond a single Kubernetes cluster.
Here are some key benefits of using SkyPilot on your Kubernetes cluster:
Simpler developer experience & built-in interactivity
SkyPilot abstracts away the complexities of Kubernetes and provides a simple interface to run AI workloads.
SkyPilot provides a seamless experience for interactive development with SSH access and integrations with VSCode and Jupyter notebooks. Developers can focus on building models and not worry about the underlying infrastructure.
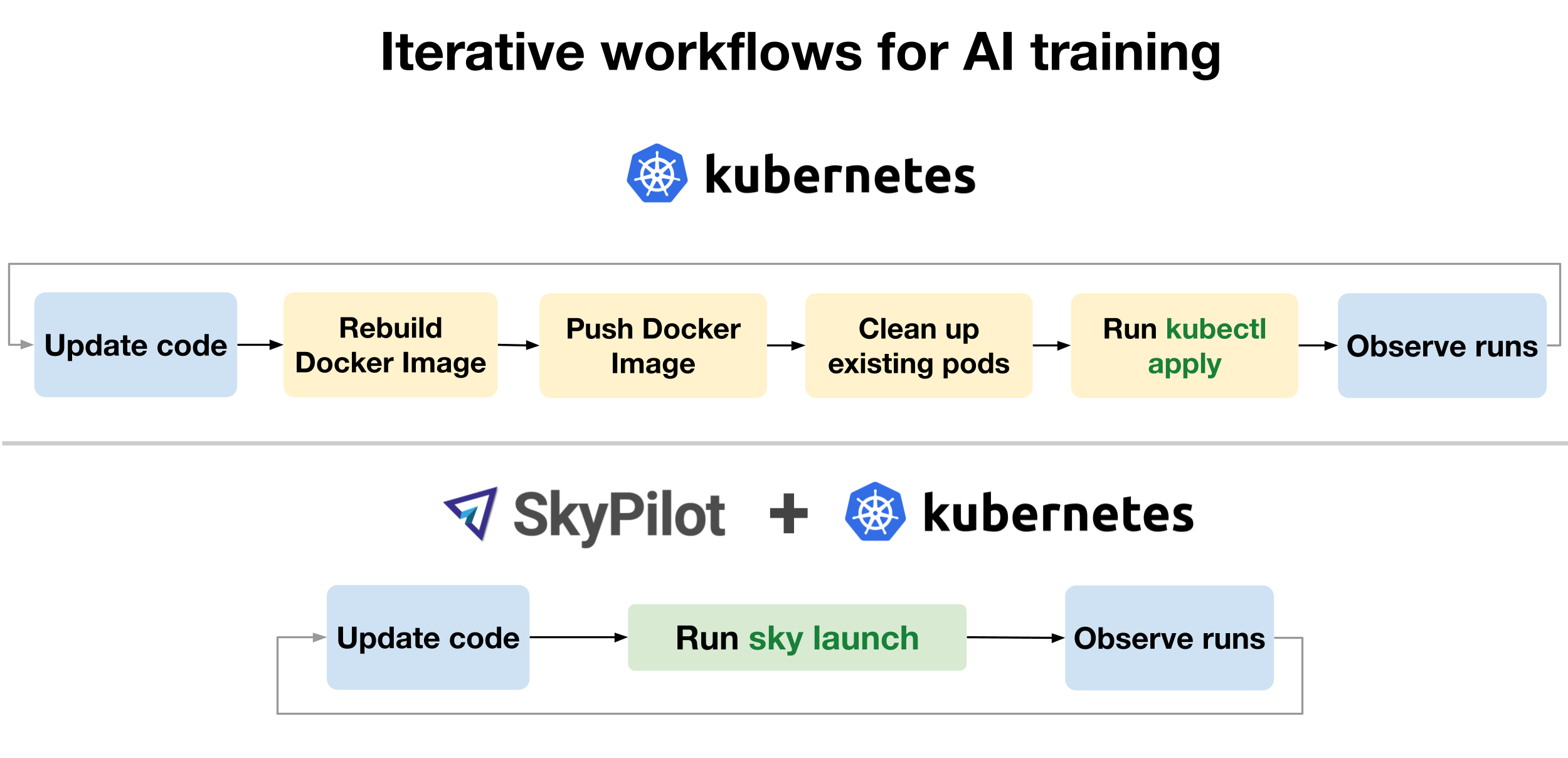
Example: iterative model development
Interactive workflows benefit from faster iteration with SkyPilot. For example, a common workflow for AI engineers is to iteratively develop and train models by tweaking code and hyperparameters by observing the training runs.
- With Kubernetes, a single iteration is a multi-step process involving building a Docker image, pushing it to a registry, updating the Kubernetes YAML and then deploying it.
- With SkyPilot, a single
sky launchtakes care of everything. Behind the scenes, SkyPilot provisions pods, installs all required dependencies, executes the job, returns logs and provides SSH access to debug.
Example: serving models
A common task after training models is serving.
Consider serving Gemma with vLLM:
- With Kubernetes, you need over 65 lines of Kubernetes YAML to launch a Gemma model served with vLLM.
- With SkyPilot, an easy-to-understand 19-line YAML launches a pod serving Gemma with vLLM.

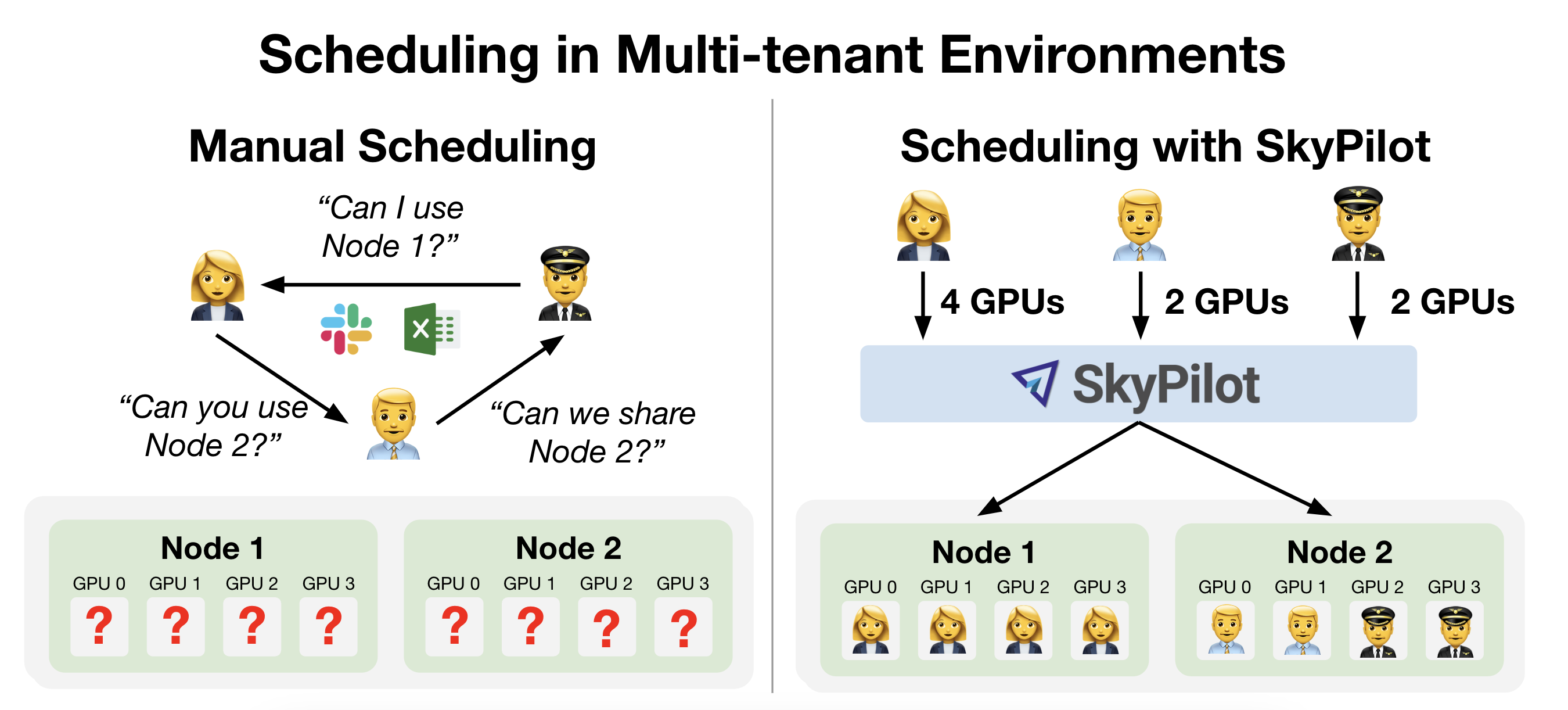
Intelligent orchestration to maximize team velocity
When running in a multi-tenant Kubernetes cluster, SkyPilot intelligently schedules GPUs across users. Each user gets their own isolated environment, ensuring that their workloads do not interfere with others while maximizing resource utilization.
No more manual scheduling of GPUs – SkyPilot takes care of it for you.
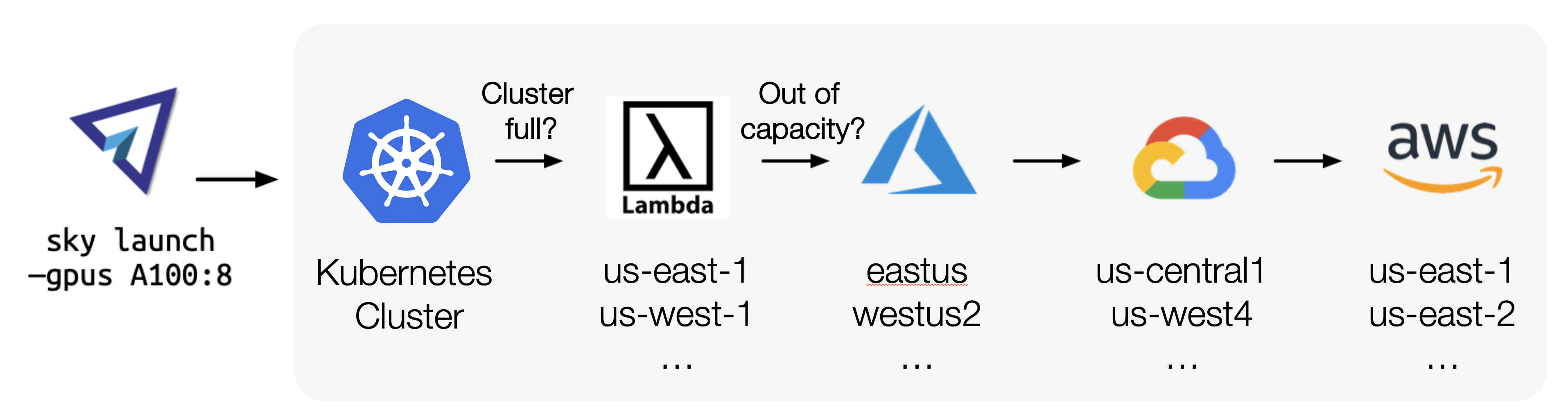
Ran out of GPUs? SkyPilot finds more at the lowest cost
GPUs are in short supply. SkyPilot is designed to maximize availability of your AI workloads by finding GPUs across your Kubernetes cluster, clouds and regions. It can automatically recover from GPU failures, spot instance preemptions and other failures.
If your on-prem cluster is running out of resources, SkyPilot can burst to the cloud and find availability wherever it exists to ensure your workloads are not blocked.
When you use the clouds, every sky launch invokes SkyPilot’s optimizer which finds the most cost-effective resources across all your infra. SkyPilot also supports spot instances on the cloud and can mix spot and on-demand instances to reduce costs by upto 6x while ensuring availability.
== Optimizer ==
Estimated cost: $0.0 / hour
Considered resources (1 node):
----------------------------------------------------------------------------------------------------------
CLOUD INSTANCE vCPUs Mem(GB) ACCELERATORS REGION/ZONE COST ($) CHOSEN
----------------------------------------------------------------------------------------------------------
Kubernetes 2CPU--8GB--1T4 2 8 T4:1 kubernetes 0.00 ✔
Azure Standard_NC4as_T4_v3 4 28 T4:1 eastus 0.53
AWS g4dn.xlarge 4 16 T4:1 us-east-1 0.53
GCP n1-highmem-4 4 26 T4:1 us-central1-a 0.59
----------------------------------------------------------------------------------------------------------
Launching a new cluster 'dev'. Proceed? [Y/n]:
Unified interface for all your infra
SkyPilot provides a unified interface to run AI workloads across on-prem, cloud and hybrid environments. The same YAML specification works across 12+ cloud providers and even your on-prem Kubernetes cluster. Once your jobs are running, sky status gives a unified view of all your resources across clouds.
$ sky status
Clusters
NAME LAUNCHED RESOURCES STATUS AUTOSTOP COMMAND
sky-serve-controller-2ea485ea 1 hr ago 1x Kubernetes(4CPU--4GB, ports=['30001-30020']... UP 10m (down) sky serve up -n llama2 ll...
sky-jobs-controller-2ea485ea 1 hr ago 1x AWS(4CPU--4GB) UP 10m (down) sky jobs launch -c bert ...
Managed jobs
In progress tasks: 1 RUNNING
ID TASK NAME RESOURCES SUBMITTED TOT. DURATION JOB DURATION #RECOVERIES STATUS
1 - bert 2x[A100:1] 3 mins ago 3m 26s 2m 18s 0 RUNNING
Services
NAME VERSION UPTIME STATUS REPLICAS ENDPOINT
llama2 1 34m 44s READY 3/3 35.225.61.44:30001
Service Replicas
SERVICE_NAME ID VERSION ENDPOINT LAUNCHED RESOURCES STATUS REGION
llama2 1 1 http://34.173.84.219:8888 1 hr ago 1x Kubernetes({'T4': 1}) READY kubernetes
llama2 2 1 http://35.199.51.206:8888 1 hr ago 1x GCP([Spot]{'T4': 1}) READY us-east4
llama2 3 1 http://34.31.108.35:8888 1 hr ago 1x Kubernetes({'T4': 1}) READY kubernetes
* To see detailed service status: sky serve status -a
* 1 cluster has auto{stop,down} scheduled. Refresh statuses with: sky status --refresh
Compatible with your existing Kubernetes tooling
SkyPilot runs like any other application on Kubernetes. Behind the scenes, it creates pods to provide compute resources to jobs and uses Kubernetes services or ingresses to expose them when required. It can also integrate with other Kubernetes controllers such as Kueue.
This means all your existing Kubernetes tooling for monitoring, logging and alerting can be used with SkyPilot.

Guide: Running AI on Kubernetes with SkyPilot
Let’s dive deeper into how to run the entire AI lifecycle – from development to training to serving – on Kubernetes with SkyPilot.
Getting started
To get started, install the latest version of SkyPilot along with Kubernetes dependencies:
pip install skypilot-nightly[kubernetes]
Next, we need to connect a Kubernetes cluster to SkyPilot.
- If you already have a Kubernetes cluster, all you need is a valid kubeconfig file. Make sure your credentials are set up in
~/.kube/configand you can access your Kubernetes cluster. You can test this by runningkubectl get nodes. - If you do not have a Kubernetes cluster, run
sky local up. This will to set up a local Kubernetes cluster for development and testing purposes.
Run sky check to verify your cluster and SkyPilot are set up correctly:
# Checks if your Kubernetes credentials are set up correctly
sky check kubernetes
You should see Kubernetes under the list of enabled clouds. If not, SkyPilot will show the reason why it is not enabled and suggest corrective steps. Refer to our docs for more details on how to set up Kubernetes.
For more advanced setups, SkyPilot can also be configured to use a custom namespace and service account.
We are now ready to launch your first SkyPilot cluster!
Connect to a GPU pod with SSH and VSCode
Initial phases of AI development require extensive interactive development on a GPU. SkyPilot lets you create “clusters”, which are a collection of pods on Kubernetes. Let’s spin up a GPU enabled SkyPilot development cluster and connect to it with SSH and VSCode.
First, let’s see what GPUs are available on the cluster with sky show-gpus --cloud kubernetes:
$ sky show-gpus --cloud kubernetes
Kubernetes GPUs
GPU QTY_PER_NODE TOTAL_GPUS TOTAL_FREE_GPUS
T4 1 4 4
V100 1, 2 4 4
To launch a cluster with a GPU for development, use sky launch:
# Launch a cluster named 'dev' with 1 NVIDIA T4 GPU. If you do not have a GPU, remove the --gpus flag.
sky launch -c dev --gpus T4:1
SkyPilot will run its optimizer to find the lowest cost and show you the cheapest option for running your development cluster:
== Optimizer ==
Estimated cost: $0.0 / hour
Considered resources (1 node):
----------------------------------------------------------------------------------------------------------
CLOUD INSTANCE vCPUs Mem(GB) ACCELERATORS REGION/ZONE COST ($) CHOSEN
----------------------------------------------------------------------------------------------------------
Kubernetes 2CPU--8GB--1T4 2 8 T4:1 kubernetes 0.00 ✔
Azure Standard_NC4as_T4_v3 4 28 T4:1 eastus 0.53
AWS g4dn.xlarge 4 16 T4:1 us-east-1 0.53
GCP n1-highmem-4 4 26 T4:1 us-central1-a 0.59
----------------------------------------------------------------------------------------------------------
Launching a new cluster 'dev'. Proceed? [Y/n]:
Your SkyPilot cluster will be launched as a pod in your Kubernetes cluster. SkyPilot will take care of launching the pod, installing dependencies, setting up SSH and more.
Once it is provisioned, you can connect to it over SSH or VSCode.
Connecting over SSH
SkyPilot automatically configures your ssh config to add an alias for the dev cluster. Accessing your cluster is as simple as running ssh <cluster>:
ssh dev
Connecting with VSCode
Another common use case for interactive development is to connect your local VSCode to a remote cluster and directly edit code that lives on the cluster. This is supported by simply connecting VSCode to the cluster with the cluster name.
- Click on the top bar, type:
> remote-ssh, and selectRemote-SSH: Connect Current Window to Host... - Select the cluster name (e.g.,
dev) from the list of hosts.

Running Jupyter notebooks
You can also launch jupyter on the cluster to get GPU-enabled notebooks. Connect to the machine and forward the port used by jupyter notebook:
ssh -L 8888:localhost:8888 dev
Inside the cluster, you can run the following commands to start a Jupyter session:
pip install jupyter
jupyter notebook
In your local browser, you should now be able to access localhost:8888 and use GPUs in your notebook:

Distributed training with SkyPilot
Once you have developed your model, you can train your model at scale with SkyPilot’s managed jobs feature.
Let’s define our training job. As an example, we will be using torch distributed data parallel (DDP) to train a BERT question-answering model on the SQuAD dataset on 2 A100 GPUs spread across two nodes:
envs:
WANDB_API_KEY: # TODO: Fill with your own wandb token, or use --env to pass.
resources:
accelerators: A100:1
# Run on two nodes with 1 GPU each
num_nodes: 2
setup: |
git clone https://github.com/huggingface/transformers.git -b v4.30.1
cd transformers
pip install -e .
cd examples/pytorch/question-answering/
pip install -r requirements.txt torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install wandb
run: |
cd transformers/examples/pytorch/question-answering/
NUM_NODES=`echo "$SKYPILOT_NODE_IPS" | wc -l`
HOST_ADDR=`echo "$SKYPILOT_NODE_IPS" | head -n1`
torchrun \
--nnodes=$NUM_NODES \
--nproc_per_node=$SKYPILOT_NUM_GPUS_PER_NODE \
--master_port=12375 \
--master_addr=$HOST_ADDR \
--node_rank=${SKYPILOT_NODE_RANK} \
run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 50 \
--max_seq_length 384 \
--doc_stride 128 \
--report_to wandb \
--run_name $SKYPILOT_TASK_ID \
--output_dir ~/checkpoints \
--save_total_limit 10 \
--save_steps 1000
You can also configure your checkpoints to be logged to a persistent volume or to a cloud bucket by changing the --output_dir flag.
To launch this job, save the above YAML to a file (e.g., bert.yaml) and run:
sky jobs launch -n bert bert.yaml
SkyPilot will provision a controller pod that will orchestrate the training job. The controller will create two pods spread across two nodes, each requesting one Nvidia A100 GPU. It will also ensure gang scheduling so that all resources are allocated at the same time.
After provisioning, SkyPilot runtime will install the required dependencies and execute the training script. Additionally, it will automatically recover from any failures, including GPU errors and NCCL timeouts.
You can monitor job status and view logs with sky jobs queue and sky jobs logs:
$ sky jobs queue
Fetching managed job statuses...
Managed jobs
In progress tasks: 1 RUNNING
ID TASK NAME RESOURCES SUBMITTED TOT. DURATION JOB DURATION #RECOVERIES STATUS
1 - bert 2x[A100:1] 3 mins ago 3m 26s 2m 18s 0 RUNNING
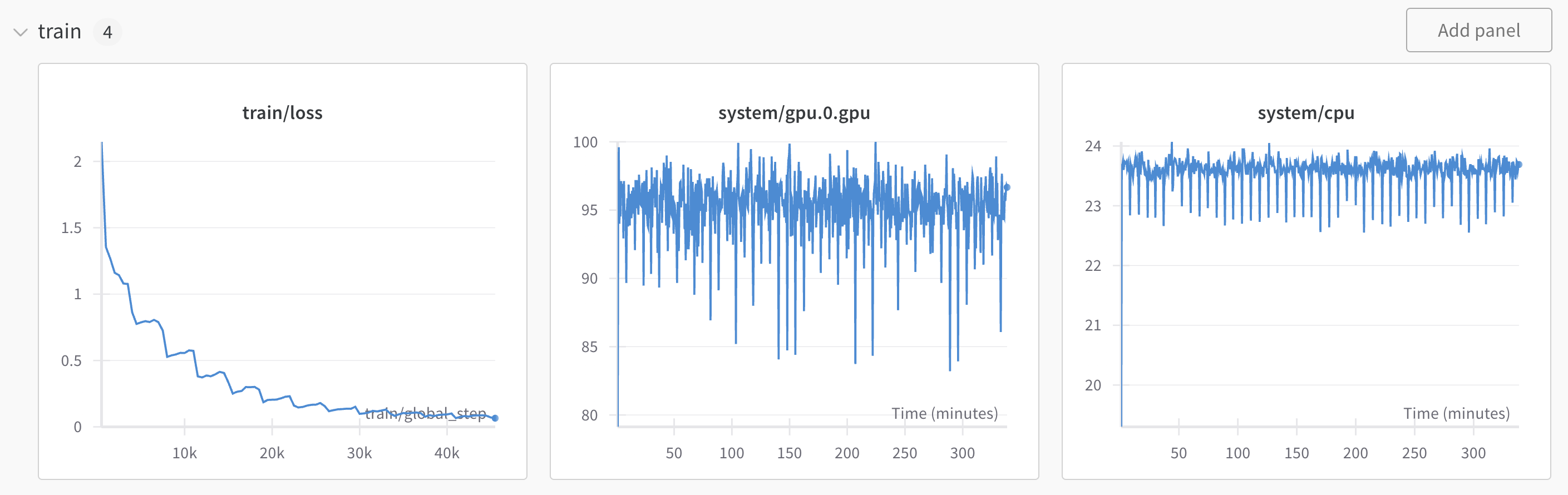
If you are using Weights and Biases (W&B) for logging, you can view the training progress on your W&B dashboard too:
If required, you can cancel jobs with sky jobs cancel. SkyPilot will terminate the pods
and clean up any resources used by the job.
Serving GenAI on Kubernetes with SkyServe
Finally, after training the model, you can serve it with SkyPilot’s SkyServe library.
- Bring any serving framework: vLLM, TGI, FastAPI, … etc.
- SkyServe provides a single endpoint for your service, backed by replicas across all your infra to ensure high availability and lowest costs.
- SkyServe manages autoscaling and load balancing and allows custom load balancing policies.
For example, to serve Google’s open source Gemma model through an OpenAI compatible endpoint, we can run vLLM on Kubernetes with this SkyPilot YAML:
envs:
MODEL_NAME: google/gemma-2b-it
HF_TOKEN: # TODO: Fill with your own huggingface token, or use --env to pass.
resources:
image_id: docker:vllm/vllm-openai:latest
accelerators: T4:1
ports: 8000
service:
readiness_probe:
path: /v1/chat/completions
post_data:
model: $MODEL_NAME
messages:
- role: user
content: Hello! What is your name?
max_tokens: 1
replicas: 3
run: |
conda deactivate
python3 -c "import huggingface_hub; huggingface_hub.login('${HF_TOKEN}')"
python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME --host 0.0.0.0 --dtype half
The service section specifies the readiness probe to check if the model is ready to serve and the number of replicas to run. You can specify autoscaling policies, configure rolling updates and more. Refer to the docs for more details.
Save the above snippet as vllm.yaml, make sure HF_TOKEN is filled in and make sure you have access to the model.
Launch the service with sky serve up:
sky serve up -n vllm vllm.yaml
SkyPilot will launch a controller that will act as the load balancer and manage the service replicas. This load balancer will provide one unified endpoint, while behind the scenes it will provision 3 pods across your Kubernetes cluster, each requesting 1 T4 GPU and using the vLLM container image for fast startup. Once the readiness probe passes on the replicas, the unified endpoint will load balance requests across the replicas.
To see the status of your service, run sky serve status:
$ sky serve status
Services
NAME VERSION UPTIME STATUS REPLICAS ENDPOINT
vllm 1 3m 53s READY 3/3 34.44.26.104:30001
Service Replicas
SERVICE_NAME ID VERSION ENDPOINT LAUNCHED RESOURCES STATUS REGION
vllm 1 1 http://34.30.184.120:8000 5 mins ago 1x Kubernetes({'T4': 1}) READY kubernetes
vllm 2 1 http://34.27.200.138:8000 5 mins ago 1x Kubernetes({'T4': 1}) READY kubernetes
vllm 3 1 http://34.70.146.169:8000 3 mins ago 1x Kubernetes({'T4': 1}) READY kubernetes
SkyServe exposes a unified endpoint address which your applications can now connect to and get completions from the Gemma model. Behind this endpoint, SkyPilot will manage the service replicas, autoscale them based on load and ensure high availability.
For example, let’s use curl on the endpoint to get completions from the Gemma model:
$ ENDPOINT=$(sky serve status --endpoint vllm)
$ curl http://$ENDPOINT/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-2b-it",
"messages": [
{
"role": "user",
"content": "Hello! What is your name?"
}
],
"max_tokens": 25
}'
Click to see output.
{
"id": "cmpl-79dc510b6e484352b74b056f6dc36028",
"object": "chat.completion",
"created": 1719526198,
"model": "google/gemma-2b-it",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! My name is Gemma, and I'm here to assist you with any questions or tasks you may have. ",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "length",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 16,
"total_tokens": 41,
"completion_tokens": 25
}
}
Scaling and updating services
You can also manually scale and update a service. For example, to scale the vLLM service to 5 replicas, update the replicas field in the YAML to 5 and run:
$ sky serve update -n vllm vllm.yaml
SkyPilot will automatically scale the service to 5 replicas. If the Kubernetes cluster runs out of resources, SkyPilot will burst to the cloud to ensure the service remains available, even under high load.
$ sky serve status
Services
NAME VERSION UPTIME STATUS REPLICAS ENDPOINT
vllm 1 18m 48s READY 5/5 34.44.26.104:30001
Service Replicas
SERVICE_NAME ID VERSION ENDPOINT LAUNCHED RESOURCES STATUS REGION
vllm 1 1 http://34.30.184.120:8000 20 mins ago 1x Kubernetes({'T4': 1}) READY kubernetes
vllm 2 1 http://34.27.200.138:8000 20 mins ago 1x Kubernetes({'T4': 1}) READY kubernetes
vllm 3 1 http://34.70.146.169:8000 18 mins ago 1x Kubernetes({'T4': 1}) READY kubernetes
vllm 4 1 http://3.182.116.201:8000 3 mins ago 1x GCP({'T4': 1}) READY us-central1
vllm 5 1 http://3.182.101.130:8000 2 mins ago 1x GCP({'T4': 1}) READY us-central1
Conclusion
Kubernetes was designed for microservices and running AI workloads on it can be challenging. SkyPilot builds on the strengths of Kubernetes to run the complete AI lifecycle through a unified interface, while providing the ability to burst beyond the Kubernetes cluster to the cloud for additional capacity. In doing so, SkyPilot guarantees high availability and low costs for your AI workloads.
Learn more:
- SkyPilot AI Gallery: a collection of popular AI workloads, including Llama-3, Mistral, Gemma, Ollama and more that can be run with SkyPilot on your Kubernetes cluster.
- SkyPilot Documentation
- GitHub
To receive latest updates, please star and watch the project’s GitHub repo, follow @skypilot_org, or join the SkyPilot community Slack.